Request Collapsing trong Backend Production: chặn cache miss fan-out và gom duplicate work trước khi DB nghẹt
Một trong những kiểu incident backend khó chịu nhất không đến từ traffic tăng 10 lần, mà đến từ rất nhiều request giống hệt nhau cùng đập vào một expensive path trong vài trăm mili giây. Cache vừa hết hạn, một key hot vừa bị evict, một downstream vừa chậm đi, hoặc một dashboard nội bộ vừa mở lại sau giờ nghỉ trưa. Từ góc nhìn business, có thể chỉ là “mọi người cùng xem một dữ liệu”. Từ góc nhìn production, đó là lúc hệ thống tự nhân bản cùng một công việc hàng chục hoặc hàng trăm lần.
Hiện tượng này thường xuất hiện dưới nhiều tên:
- thundering herd;
- cache stampede;
- duplicate concurrent work;
- request fan-out on cache miss;
- dogpile effect.
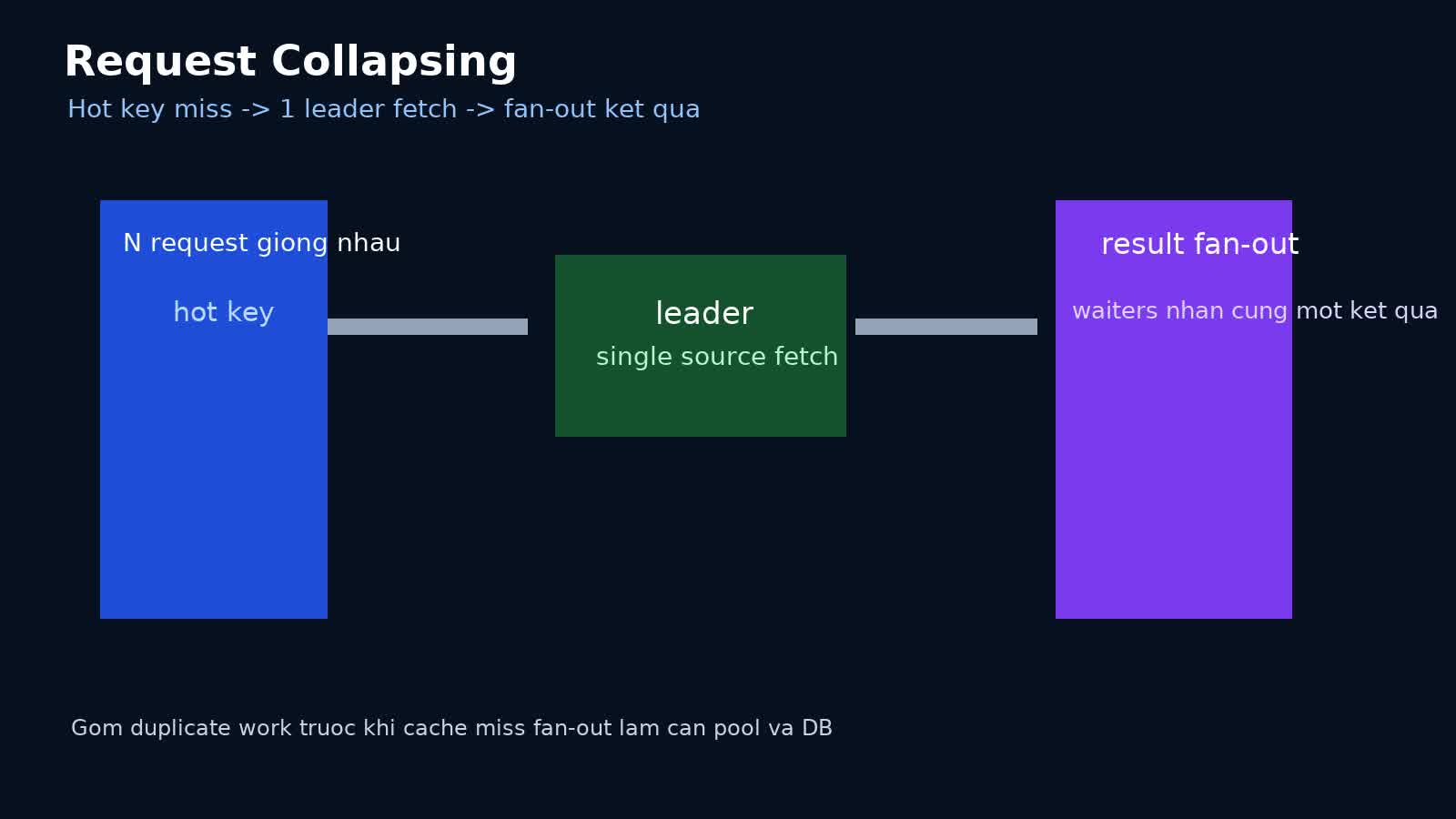
Request collapsing là kỹ thuật gom các request concurrent cùng cần một kết quả thành một lần tính toán hoặc một lần fetch thực sự, rồi fan-out kết quả cho các caller đang chờ. Ý tưởng nghe đơn giản, nhưng khi đem vào production nó liên quan trực tiếp tới correctness, latency tail, timeout budget, cache strategy, lock granularity và observability.
Bài này đi sâu vào request collapsing dưới góc backend engineering + database performance + production engineering: khi nào nó đáng làm, khi nào nó biến thành global bottleneck, cách thiết kế per-key coalescing, stale fallback, failure propagation và metric để tránh tự tin sai.
Request collapsing thực chất là gì?

Request collapsing là cơ chế đảm bảo rằng nếu nhiều request cùng lúc hỏi một logical resource giống nhau, hệ thống chỉ để một leader thực hiện expensive work, còn các request khác sẽ:
- chờ kết quả của leader trong một cửa sổ ngắn; hoặc
- nhận stale value/fallback; hoặc
- bị fail fast theo policy rõ ràng.
Ví dụ kinh điển:
- key cache
product:123vừa miss; - 200 request cùng đến trong 80ms;
- nếu không collapsing, application có thể bắn 200 query giống nhau xuống database;
- nếu có collapsing, 1 request query DB, 199 request còn lại đợi hoặc nhận stale value.
Điểm quan trọng: request collapsing không phải cache. Nó thường đứng ở ranh giới giữa cache và source of truth để giảm duplicate work trong lúc cache miss, recompute hoặc refresh.
Vì sao production cần request collapsing thay vì chỉ tăng cache TTL?
Tăng TTL đôi khi giúp, nhưng không giải quyết mọi case.
1. Có dữ liệu cần freshness khá cao
Một số data path không thể giữ TTL dài một cách vô tư:
- inventory còn/không còn;
- pricing động;
- quota còn lại;
- dashboard vận hành gần realtime;
- permission snapshot có thể đổi trong ngày.
Nếu chỉ kéo TTL lên để né stampede, anh đang đổi correctness/freshness lấy sự yên ổn tạm thời.
2. Hot key có thể vẫn gây bão đúng lúc hết hạn
Ngay cả TTL 5 phút cũng không cứu được nếu một key rất nóng hết hạn đúng lúc traffic dồn vào. Hệ thống vẫn có thể hứng hàng trăm miss cùng lúc trong một cửa sổ rất ngắn.
3. Expensive work không chỉ là database query
Duplicate work có thể là:
- query nhiều bảng rồi serialize response nặng;
- gọi vendor API bị rate limit;
- render permission graph;
- build personalized aggregate;
- tính recommendation batch nhỏ theo user segment.
Khi đó, ngay cả khi DB chưa chết, CPU application hoặc upstream quota có thể chết trước.
Pattern phổ biến: per-key singleflight
Cách an toàn và thực dụng nhất là coalescing theo key, không phải global mutex.
Pseudo-flow:
- request đến với logical key, ví dụ
report:team-42:2026-06-26; - kiểm tra cache;
- nếu hit, trả luôn;
- nếu miss, thử đăng ký làm leader cho key đó;
- nếu trở thành leader, fetch/compute dữ liệu;
- ghi cache;
- đánh thức waiters;
- waiters lấy kết quả vừa được tạo hoặc nhận direct handoff.
Điều làm pattern này mạnh là lock scope hẹp: chỉ request cho cùng key mới chờ nhau.
Sai lầm phổ biến: biến request collapsing thành điểm nghẽn toàn cục
Nhiều hệ thống làm sai ở bước đầu tiên: dùng một mutex/global semaphore duy nhất cho mọi miss. Khi đó một key nóng có thể làm chậm cả key lạnh.
Đây là anti-pattern vì:
- unrelated keys bị head-of-line blocking;
- một leader chậm làm toàn bộ request miss path bị xếp hàng;
- tail latency tăng ngay cả khi load tổng không quá lớn.
Rule thực chiến: collapse theo key hoặc shard nhỏ, gần như không bao giờ collapse toàn bộ subsystem bằng một khóa chung.
Request collapsing khác gì cache stampede protection?
Thực tế chúng chồng lấn mạnh, nhưng không hoàn toàn giống nhau.
- Cache stampede protection tập trung vào việc tránh nhiều worker cùng recompute khi cache hết hạn.
- Request collapsing rộng hơn: gom duplicate work ở mọi nơi có concurrent identical demand, kể cả khi không dùng TTL cache truyền thống.
Một hệ thống tốt thường kết hợp cả hai:
- soft TTL/hard TTL;
- stale-while-revalidate;
- per-key singleflight khi miss;
- jitter để tránh nhiều key hết hạn cùng nhịp.
Khi nào request collapsing đem lại ROI rất cao?
1. Hot read path có skew mạnh
Một số key chiếm phần lớn traffic:
- trang sản phẩm hot;
- config tenant lớn;
- dashboard executive;
- feed aggregate cho cùng một segment.
Skew càng mạnh, coalescing càng đáng giá.
2. Expensive source có concurrency limit rõ ràng
Ví dụ:
- connection pool database dễ cạn;
- upstream API có rate limit 100 rps;
- service nội bộ có p99 cao và queue ngắn;
- Redis hoặc search cluster đang gần ngưỡng saturation.
Khi duplicate work bị cắt từ 50 request xuống 1 request, giá trị không chỉ là latency mà còn là bảo toàn capacity margin.
3. Business chấp nhận cửa sổ chờ ngắn hoặc stale fallback
Nếu caller có thể chờ thêm 30-100ms để lấy cùng một kết quả, hoặc chấp nhận stale value trong lúc refresh, collapsing thường dễ triển khai hơn nhiều.
Timeout budget: waiters không được chờ vô hạn

Một hệ thống request collapsing non-trivial phải có timeout policy rõ ràng. Nếu không, anh chỉ đổi từ “200 query cùng chạy” sang “200 request cùng treo”.
Có ba nguyên tắc quan trọng:
1. Waiter phải tôn trọng remaining deadline của chính request đó
Nếu request chỉ còn 120ms budget, waiter không được chờ leader 500ms chỉ vì lock policy mặc định là vậy.
2. Leader timeout và waiter timeout không nhất thiết giống nhau
Leader có thể được phép dùng budget dài hơn một chút để tạo ra giá trị cho nhiều request, nhưng vẫn phải có trần cứng. Nếu leader chạy vô định, cả nhóm caller sẽ bị kéo chìm.
3. Khi timeout xảy ra, phải quyết định rõ hành vi fallback
Các lựa chọn hợp lý tùy use case:
- trả stale cache nếu còn;
- fail fast với mã lỗi có thể quan sát;
- cho waiter tự đi source-of-truth nếu policy cho phép;
- degrade sang response nhẹ hơn.
Điều không nên làm là để waiter silently detach rồi sinh thêm duplicate work không kiểm soát.
Stale-while-revalidate: lớp đệm rất hợp với request collapsing
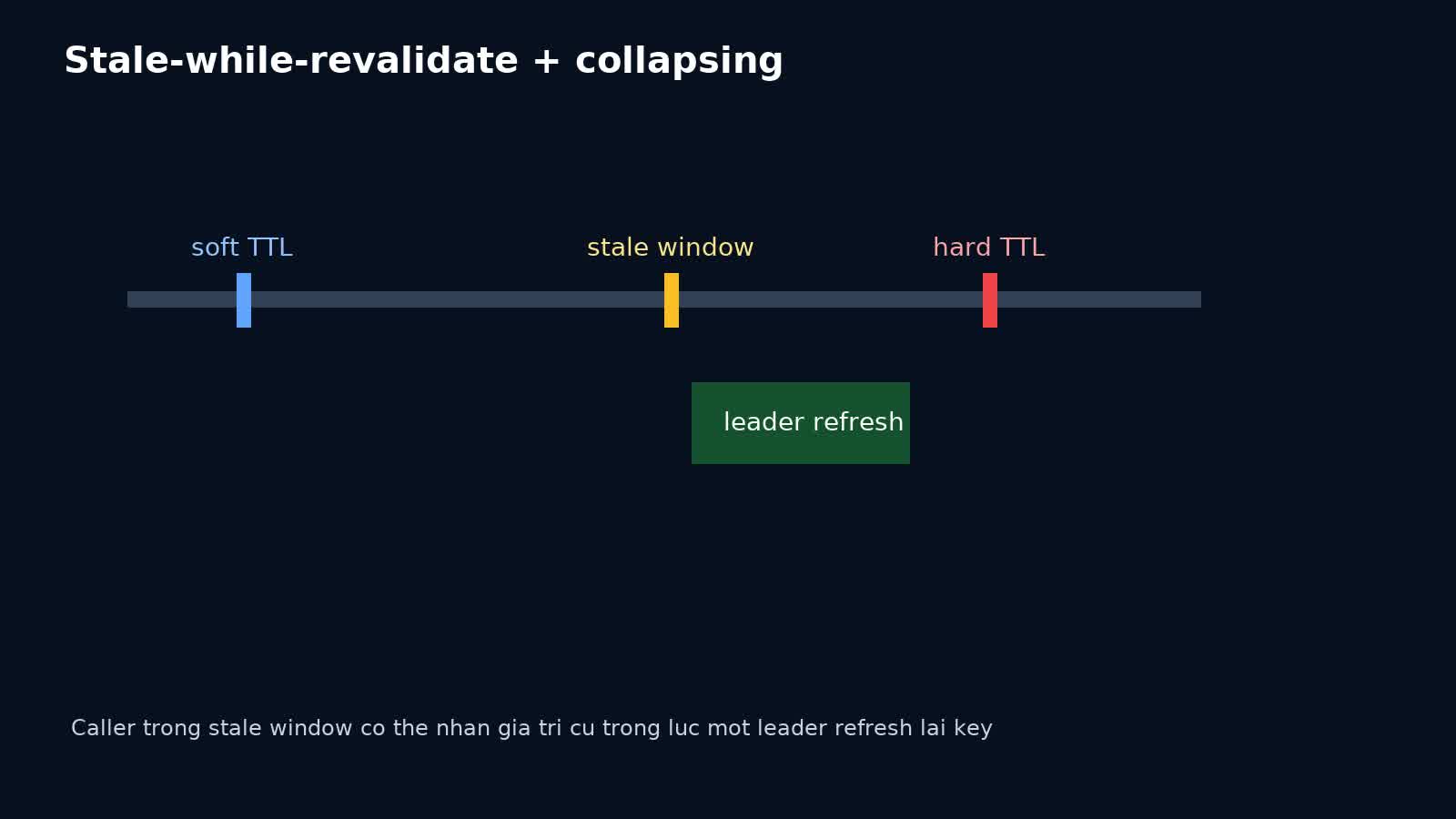
Một trong những kết hợp hiệu quả nhất là:
- cache có soft TTL;
- khi soft TTL hết, request đầu tiên thành leader để refresh;
- các request khác vẫn nhận stale value trong cửa sổ ngắn;
- nếu refresh thành công, cache được cập nhật;
- nếu refresh lỗi, stale value có thể được kéo dài trong emergency window có kiểm soát.
Mô hình này đặc biệt hữu ích cho:
- dashboard nội bộ;
- config read-heavy;
- danh sách top items;
- aggregate không cần realtime tuyệt đối.
Nó giúp hệ thống tránh cả hai cực đoan:
- vừa không ép mọi request chờ refresh;
- vừa không để hàng trăm request cùng tự refresh.
Failure propagation: leader fail thì waiters nhận gì?
Đây là chỗ nhiều implementation non-production bị hỏng.
Nếu leader thất bại, waiters cần nhận một outcome nhất quán. Có vài lựa chọn:
Fail cùng một lỗi
Phù hợp khi source of truth đang lỗi rõ ràng và stale không an toàn.
Nhận stale fallback
Phù hợp khi dữ liệu hơi cũ vẫn tốt hơn lỗi trắng.
Cho một số waiter retry có kiểm soát
Chỉ hợp lý nếu có guardrail: retry budget, jitter, concurrency cap. Nếu mọi waiter cùng “tự cứu mình” sau khi leader fail, anh vừa tái tạo stampede.
Request collapsing với distributed systems: local process hay distributed lock?
Local process coalescing
Nếu phần lớn duplicate requests đi vào cùng một instance, in-memory singleflight là cách rẻ và nhanh nhất. Nó không cần round-trip lock ra ngoài, ít moving parts, dễ instrument.
Nhược điểm là duplicate work vẫn có thể xảy ra giữa nhiều instance.
Distributed coalescing
Nếu traffic phân tán đều qua nhiều node, một hot key có thể cùng miss trên nhiều instance. Khi đó có thể cần:
- Redis short-lived lock;
- lease token theo key;
- shared “in flight” marker;
- hoặc architecture khác như refresh worker riêng.
Nhưng distributed lock không phải miễn phí. Nó mang theo các rủi ro:
- lock orphan;
- clock/lease drift;
- network partition;
- lock service thành dependency mới;
- contention ở Redis chính nó.
Vì vậy, đừng nhảy vào distributed coalescing nếu local collapsing + TTL jitter + stale fallback đã đủ giảm 80% vấn đề.
Database performance: request collapsing giúp gì cho pool và query latency?
Ở tầng database, lợi ích dễ thấy nhất là giảm số query giống nhau cùng chạm vào:
- cùng một row hot;
- cùng một index hot range;
- cùng một aggregate expensive;
- cùng một cache-miss query join nặng.
Tác động tốt thường đến theo chuỗi:
- ít query duplicate hơn;
- pool ít wait hơn;
- lock contention ít hơn;
- buffer cache ổn định hơn;
- tail latency bớt vỡ;
- ít kéo theo retry ở upstream.
Nói cách khác, request collapsing không chỉ giảm DB QPS. Nó giảm đúng loại QPS vô ích nhất: QPS không tạo thêm business value.
Nhưng đừng lạm dụng: có những path không nên collapse
1. Response quá cá nhân hóa theo request
Nếu mỗi request khác nhau theo permission, locale, pricing context hoặc experiment bucket, việc cố coalescing có thể tạo bug correctness còn tệ hơn cả load spike.
2. Write path có side effect
Coalescing write path chỉ an toàn khi business semantics thật sự cho phép và idempotency được thiết kế nghiêm túc. Nếu không, rất dễ che mất duplicate write bug hoặc làm caller hiểu sai trạng thái.
3. Key cardinality quá cao, hit ratio gom quá thấp
Nếu gần như không có duplicate concurrent requests cho cùng key, overhead quản lý inflight map/lock có thể lớn hơn lợi ích.
Observability: metric nào cho thấy collapsing đang cứu hệ thống thay vì che vấn đề?

Ít nhất nên có các metric sau:
- cache hit rate và miss rate theo key class;
- số leader được tạo;
- số waiter attach vào leader;
- collapse fan-in trung bình và p95;
- thời gian waiter chờ;
- số lần waiter timeout;
- stale fallback rate;
- source fetch latency khi có leader;
- số lần leader fail;
- duplicate work prevented estimate.
Ngoài ra nên log hoặc trace được:
- logical key;
- leader/waiter role;
- remaining deadline;
- fallback path;
- source latency;
- outcome cuối.
Nếu không có metric fan-in và waiter timeout, anh sẽ rất khó trả lời câu hỏi quan trọng nhất: collapsing đang giúp giảm load hay đang chỉ dồn request vào một chỗ khác?
Một design thực dụng cho production
Một policy khá cân bằng cho hot read path có thể là:
- đọc cache với soft TTL + hard TTL;
- nếu hit trong hard TTL nhưng quá soft TTL, trả stale cho caller hiện tại và trigger refresh có coalescing;
- nếu miss hoàn toàn, cho một leader fetch source;
- waiter được chờ tối đa theo remaining deadline, ví dụ min(80ms, remaining_budget - safety_margin);
- nếu leader chưa xong mà stale còn usable, waiter nhận stale;
- nếu không có stale, fail fast có observability thay vì tự sinh thêm 20 fetch song song;
- tất cả refresh/miss path đều có jitter và retry cực hạn chế.
Đây không phải công thức duy nhất, nhưng nó phản ánh một nguyên tắc production rất quan trọng: ưu tiên bảo vệ hệ thống khỏi duplicate work trước, rồi mới tối ưu freshness tới mức hoàn hảo.
Checklist trước khi anh triển khai request collapsing
- duplicate work hiện tại có được đo hay chỉ là cảm giác?
- hot key nào đang tạo phần lớn pain?
- collapse key đã bao phủ đủ dimension correctness chưa?
- waiter có timeout theo remaining budget chưa?
- leader fail thì stale/fallback là gì?
- implementation là local hay distributed, và dependency mới là gì?
- metric nào chứng minh load thực sự giảm ở DB/upstream?
- có tránh được việc waiters tự nổ thêm retry khi leader chậm không?
Kết luận
Request collapsing là một trong những kỹ thuật có tỷ lệ effort/impact rất tốt cho backend production khi hệ thống có hot keys, expensive reads và cache miss fan-out. Nó không hào nhoáng như thêm cluster mới hay “scale database”, nhưng thường xử lý đúng gốc của một lớp tải vô ích: nhiều request giống nhau cùng làm lại một công việc.
Nếu anh đang thấy những pattern như cache miss spike, pool wait tăng ngắn hạn, dashboard bị đập bởi key nóng, hoặc downstream bị bắn duplicate fetch sau mỗi lần TTL hết hạn, request collapsing đáng để ưu tiên hơn việc chỉ tăng TTL hoặc tăng tài nguyên. Làm đúng, nó giảm load, giảm tail latency và tăng khoảng thở cho cả application lẫn database. Làm sai, nó chỉ biến stampede thành queue treo.
Điểm khác biệt nằm ở những chi tiết production nhỏ nhưng quyết định: per-key scope, deadline-aware waiting, stale fallback, failure discipline và observability đủ tốt để biết mình đang chặn duplicate work hay chỉ dời chỗ nghẽn.
Bài liên quan nên đọc tiếp
- Cache Stampede trong Backend Production — để so sánh request collapsing với stale-while-revalidate và anti-dogpile rộng hơn.
- Retry Storm và Timeout Budget trong Backend Production — khi waiter timeout và retry sai có thể tự khuếch đại incident.
- PostgreSQL Query Plan Regression trong Production — để thấy duplicate read load và query plan xấu có thể cộng hưởng ra sao ở database.
- Adaptive Concurrency Limits trong Backend Production — lớp guardrail tốt khi source fetch của leader vẫn có nguy cơ làm cạn tài nguyên.
- Backpressure và Load Shedding trong Backend — khi collapsing chưa đủ và hệ thống vẫn cần degrade có chủ đích.