Backend production không chỉ sập vì bug. Rất nhiều hệ thống sập vì một nguyên nhân khó chịu hơn: nhận nhiều việc hơn khả năng xử lý, rồi cố xử lý tất cả cho đến khi mọi thứ cùng chết.
Khi traffic tăng đột biến, database chậm, downstream timeout, queue backlog, thread pool đầy hoặc CPU chạm trần, câu hỏi quan trọng không còn là “làm sao xử lý hết request?”. Câu hỏi đúng hơn là: request nào nên nhận, request nào nên làm chậm lại, request nào nên từ chối sớm để bảo vệ phần lõi của hệ thống?
Đó là lúc cần hiểu backpressure backend và load shedding backend. Bài này đi theo góc nhìn production: tín hiệu quá tải, giới hạn concurrency, queue, timeout, circuit breaker, rate limit, graceful degradation và checklist rollout.

Backpressure là gì trong backend production?
Backpressure là cơ chế để một thành phần đang quá tải gửi tín hiệu ngược về upstream rằng: “đừng đẩy thêm việc vào tôi nhanh như vậy”.
Trong hệ thống backend, backpressure có thể xuất hiện ở nhiều tầng: API gateway giới hạn request rate hoặc concurrency; service A giảm tốc gọi service B khi B timeout; worker không pull thêm job khi queue hoặc database quá tải; streaming consumer commit offset chậm lại khi downstream xử lý không kịp; thread pool từ chối task mới thay vì để hàng đợi phình vô hạn.
Điểm cốt lõi: backpressure không chỉ là tối ưu performance. Nó là cơ chế kiểm soát dòng chảy để tránh một điểm nghẽn kéo sập toàn bộ chuỗi phụ thuộc.
Load shedding là gì và khác backpressure ra sao?
Load shedding là hành động chủ động từ chối, bỏ qua hoặc degrade một phần workload khi hệ thống vượt ngưỡng an toàn. Nếu backpressure là “làm chậm dòng vào”, thì load shedding là “cắt bớt tải để phần quan trọng còn sống”.
- Trả
429 Too Many Requestscho client vượt quota. - Trả
503 Service UnavailablekèmRetry-Afterkhi service quá tải. - Bỏ qua request analytics/tracking không quan trọng.
- Tắt recommendation block nhưng vẫn cho checkout hoạt động.
- Không chạy job report nặng trong giờ cao điểm.
- Drop message duplicate hoặc stale trong queue nếu giá trị nghiệp vụ đã hết.
Trong production, từ chối sớm một phần request thường tốt hơn để tất cả request timeout sau 30 giây.
Vì sao chỉ autoscaling là không đủ?
Autoscaling hữu ích, nhưng không thay thế backpressure. Scale có độ trễ; bottleneck có thể nằm ở database, Redis, Kafka, search engine hoặc third-party API; tăng instance có thể mở thêm connection và làm dependency tệ hơn; retry storm có thể nhân traffic nhanh hơn tốc độ scale; queue backlog không biến mất ngay; và cost không vô hạn.
Autoscaling trả lời câu hỏi “có thêm năng lực xử lý không?”. Backpressure trả lời câu hỏi “khi năng lực không đủ, hệ thống phản ứng thế nào?”. Hai thứ phải đi cùng nhau.
Các tín hiệu quá tải cần đo trước khi chặn tải

1. Latency theo percentile
Đừng chỉ nhìn average latency. Khi p95 hoặc p99 tăng mạnh, hệ thống có thể đã bắt đầu queue nội bộ dù p50 vẫn đẹp.
2. Saturation của pool
Theo dõi thread pool, worker queue, database connection pool, HTTP client pool, Redis connection pool và Kafka consumer lag. Nếu pool đầy, tăng timeout thường chỉ làm sự cố kéo dài hơn.
3. Error và timeout từ dependency
Một downstream bắt đầu trả lỗi hoặc timeout là tín hiệu cần giảm tốc. Nếu upstream vẫn retry vô hạn, lỗi nhỏ sẽ thành cascading failure.
4. Queue depth và queue age
Queue length chưa đủ. Cần đo cả tuổi của message/job cũ nhất. Queue có ít job nhưng job cũ nhất đã 30 phút nghĩa là workload có thể đã stale hoặc worker không theo kịp.
5. CPU, memory, GC, event loop lag
Với Node.js, event loop lag rất quan trọng. Với JVM, GC pause và heap pressure có thể làm latency nhảy vọt. Với Go, goroutine leak hoặc channel backlog tạo áp lực khác.
6. Business priority
Checkout, thanh toán, login, submit form có thể ưu tiên cao hơn export report, recommendation, view counter hoặc analytics beacon. Nếu không phân loại priority từ trước, lúc incident team sẽ không biết nên cắt gì.
Thiết kế backpressure ở các tầng backend
Tầng API gateway / edge
Gateway phù hợp để rate limit theo IP/user/API key/tenant, concurrency limit theo route, request body size limit, timeout ngắn cho endpoint public và quota riêng cho integration partner. Rate limit không nên chỉ là một số global; endpoint đọc nhẹ, đọc nặng, ghi, gọi third-party và export/report cần ngân sách khác nhau.
Tầng application service
Trong service, backpressure thường nằm ở concurrency và timeout. Tránh pattern tạo async task vô hạn rồi gọi DB/HTTP dependency với timeout dài. Cách tốt hơn là giới hạn request đang xử lý theo route, dùng bounded queue, timeout ngắn hơn SLA tổng, hủy request khi client disconnect nếu phù hợp, không retry thao tác non-idempotent khi thiếu idempotency key và trả lỗi sớm khi pool gần đầy.
SLA endpoint: 800ms
Budget:
- validate/auth: 50ms
- DB query: 250ms
- downstream API: 300ms
- render/serialize: 100ms
- buffer: 100msTầng database và connection pool
Database thường là nơi đau nhất. Thấy connection pool đầy rồi tăng max_connections có thể làm context switching, lock wait và memory usage tệ hơn. Hãy thiết kế pool size theo khả năng DB thật, statement timeout, query timeout, giới hạn concurrency cho job nặng và không cho request public kích hoạt query scan lớn. Nếu cần đọc thêm về tối ưu database, xem Index trong PostgreSQL.
Tầng queue và worker
Queue giúp tách request khỏi xử lý nền, nhưng queue không tự giải quyết overload. Queue tốt cần bounded producer rate, worker concurrency có kiểm soát, retry backoff+jitter, dead-letter queue, idempotent handler, priority queue nếu cần, visibility timeout hợp lý và metric queue age. Với event-driven system, Outbox Pattern trong Backend giúp side effect đáng tin cậy hơn.
Pattern load shedding thực tế
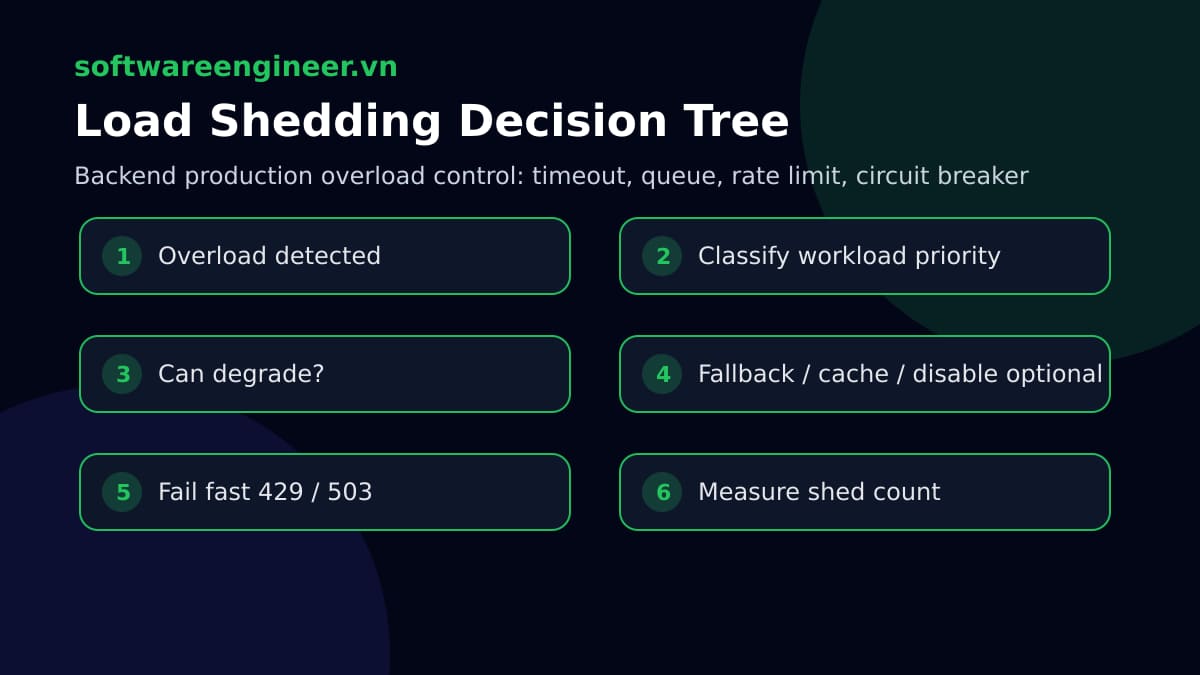
1. Fail fast với lỗi rõ ràng
Khi hệ thống đã quá tải, trả lỗi nhanh thường tốt hơn timeout lâu. Dùng 429 cho vượt quota, 503 cho service tạm quá tải, và thêm Retry-After nếu client có thể retry.
HTTP/1.1 503 Service Unavailable
Retry-After: 30
Content-Type: application/json
{"error":"service_overloaded","retry_after_seconds":30}2. Circuit breaker cho dependency
Circuit breaker ngăn service tiếp tục gọi một dependency đã hỏng. Trạng thái thường gồm closed, open và half-open. Nó không che lỗi mãi mãi; nó tránh đổ thêm tải vào dependency đang chết và giúp hệ thống hồi phục.
3. Graceful degradation
Không phải mọi tính năng đều phải hoạt động trong peak traffic. Ecommerce có thể giữ checkout/login, degrade recommendation và delay analytics. SaaS có thể giữ core API, retry webhook nền, cache dashboard chart và hoãn bulk export. Graceful degradation cần feature flag, fallback cache và config runtime chuẩn bị trước.
4. Priority và fairness
Nếu hệ thống multi-tenant, load shedding cần tránh để một tenant lớn làm nghẹt toàn bộ. Dùng quota theo tenant, token bucket theo API key, concurrent cap theo organization, queue riêng theo priority hoặc weighted fair queueing.
5. Drop workload stale
Một số job quá cũ thì xử lý cũng không còn giá trị: notification “user đang online” sau 20 phút, refresh cache cho key đã invalidated, sync trạng thái tạm thời đã hết hạn. Với workload này, nên có TTL hoặc rule drop stale job.
Retry storm: kẻ khuếch đại overload

Retry đúng giúp vượt lỗi tạm thời. Retry sai biến lỗi nhỏ thành traffic multiplier. Nếu traffic bình thường là 1.000 request/s, downstream timeout 30%, client retry tối đa 3 lần không jitter, nhiều request sẽ cùng retry đúng lúc dependency chưa hồi phục.
Retry policy an toàn hơn: chỉ retry lỗi tạm thời; không retry vô điều kiện với 4xx; exponential backoff; jitter; retry budget; idempotency key cho request ghi; timeout tổng cho toàn bộ request, không chỉ từng attempt. Bài thiết kế API idempotent nối trực tiếp với phần này.
Một kiến trúc tham chiếu cho backend chống quá tải
Client
-> CDN/WAF
-> API Gateway: rate limit + request timeout + body limit
-> Backend Service:
- per-route concurrency limit
- bounded internal queue
- circuit breaker for downstream
- timeout budget
- fallback/degradation
-> Database/Cache/Queue:
- connection pool budget
- query timeout
- worker concurrency control
- queue age monitoring
-> Observability:
- latency p95/p99
- saturation
- error rate
- retry count
- shed countMetric quan trọng là shed count. Nếu chủ động drop/từ chối request, hãy đo nó. Nếu không đo, team sẽ không biết hệ thống đang sống nhờ load shedding hay thật sự khỏe. Khi cần debug request xuyên service, đọc thêm Distributed Tracing cho Microservices.
Checklist triển khai backpressure và load shedding
Trước khi triển khai
- Liệt kê endpoint/workload theo business priority.
- Xác định dependency chính: DB, cache, queue, third-party API.
- Đo p95/p99 latency, error rate, pool saturation, queue age.
- Có dashboard cho request rate, retry rate, timeout, shed count.
- Có log structured cho lý do shed: rate_limit, concurrency_limit, dependency_unhealthy, queue_full.
Trong code/service
- Đặt timeout budget theo endpoint.
- Dùng bounded queue thay vì queue vô hạn.
- Giới hạn concurrency cho endpoint nặng.
- Cấu hình circuit breaker cho dependency quan trọng.
- Retry có exponential backoff + jitter.
- Không retry request ghi nếu thiếu idempotency.
- Có fallback hoặc degrade path cho tính năng phụ.
- Trả lỗi rõ ràng với
429/503vàRetry-After.
Ở tầng vận hành
- Alert khi p95/p99 vượt ngưỡng.
- Alert khi pool saturation gần max trong nhiều phút.
- Alert khi queue age vượt SLA.
- Runbook ghi rõ feature flag nào có thể tắt.
- Load test có kịch bản dependency chậm, không chỉ traffic tăng.
- Chaos/drill nhẹ để kiểm tra circuit breaker và fallback.
Phần rollout nên đi cùng checklist deploy backend lên production, vì thay đổi timeout/rate limit/circuit breaker có thể ảnh hưởng trực tiếp user.
Sai lầm thường gặp
Queue vô hạn
Queue vô hạn thường chỉ che giấu overload. Request không biến mất; nó chuyển thành latency, memory pressure hoặc backlog. Nếu cần queue, hãy có giới hạn và hành vi khi đầy: reject, drop stale, spillover hoặc degrade.
Timeout quá dài
Timeout dài làm user chờ lâu và giữ tài nguyên lâu. Timeout phải dựa trên SLA, không dựa trên “để chắc ăn”.
Retry không jitter
Retry đồng loạt tạo sóng traffic. Jitter phân tán retry, giảm khả năng tạo spike mới.
Tăng worker khi DB đã nghẹt
Nếu DB là bottleneck, tăng worker có thể làm DB chết nhanh hơn. Cần nhìn saturation của dependency, không chỉ backlog.
Không phân loại request quan trọng
Nếu mọi request đều cùng priority, lúc quá tải hệ thống sẽ tự chọn ngẫu nhiên request nào fail. Thường đó không phải lựa chọn kinh doanh tốt.
Nên bắt đầu từ đâu nếu hệ thống chưa có gì?
- Đặt timeout budget rõ cho 3 endpoint quan trọng nhất.
- Thêm concurrency limit cho endpoint/job nặng nhất.
- Đo database connection pool saturation và queue age.
- Thêm retry backoff + jitter cho outbound calls.
- Viết runbook: khi quá tải, tắt/degrade phần nào trước.
Kết luận
Backpressure và load shedding không làm hệ thống mạnh vô hạn. Chúng giúp hệ thống biết tự bảo vệ khi vượt ngưỡng: đo đang quá tải ở đâu, giảm tốc upstream đúng chỗ, từ chối sớm request ít quan trọng, bảo vệ dependency lõi, degrade tính năng phụ thay vì sập toàn bộ và hồi phục có kiểm soát sau spike.
Nếu team chỉ tối ưu happy path, incident sẽ đến từ overload path. Overload path nên được thiết kế như một phần chính thức của kiến trúc. Sau khi triển khai, hãy dùng incident postmortem blameless để học từ các đợt quá tải thật và cải tiến ngưỡng, runbook, dashboard.