PostgreSQL Query Plan Regression trong Production: vì sao query đang ổn bỗng chậm sau một lần deploy hoặc ANALYZE
Có những incident rất khó chịu ở tầng database: không có lỗi rõ ràng, CPU chưa chắc đã chạm trần, disk chưa chắc đỏ rực, code business nhìn qua cũng gần như không đổi, nhưng một nhóm request quan trọng bỗng tăng latency gấp 5–20 lần. Điều khiến nhiều team mất thời gian nhất là query vẫn là query đó, index vẫn đang tồn tại, data model không có vẻ “hỏng”, vậy tại sao hôm qua còn ổn mà hôm nay lại chậm?
Rất nhiều case như vậy thực chất là query plan regression: PostgreSQL planner đổi sang một execution plan tệ hơn cho distribution dữ liệu hiện tại, cho một parameter cụ thể, hoặc sau khi statistics vừa được cập nhật. Nếu debug sai hướng, team rất dễ làm những việc gây hại lâu dài như:
- tắt planner feature chỉ vì một query lỗi;
- ép
enable_nestloop = offhoặcenable_seqscan = offở cấp hệ thống; - thêm index mới mà không xử lý gốc vấn đề cardinality estimation;
- blame ORM dù root cause nằm ở statistics hoặc parameter sensitivity;
- chạy
VACUUM FULLhoặc restart database như một nghi thức tâm linh.
Bài này nhìn query plan regression dưới góc production engineering cho backend/database engineer, không phải kiểu tutorial nhập môn. Mục tiêu là trả lời các câu hỏi quan trọng:
- regression thường đến từ đâu trong PostgreSQL;
- khi nào lỗi nằm ở statistics, khi nào nằm ở data distribution, khi nào nằm ở generic plan;
- cách đọc
EXPLAIN (ANALYZE, BUFFERS)mà không tự lừa mình; - dùng
pg_stat_statements,pg_stats,ANALYZE,default_statistics_target, extended statistics thế nào cho đúng tình huống; - khi nào nên sửa SQL/index/schema, khi nào chỉ cần làm mới statistics, và khi nào mới nên động tới planner knobs.
Query plan regression thực chất là gì?
Planner của PostgreSQL không “thực thi để xem cái nào nhanh hơn rồi chọn”. Nó ước lượng chi phí của các phương án khác nhau dựa trên statistics, cost model và một số assumption về dữ liệu. Khi assumption đó lệch thực tế, planner có thể chọn một plan rất tệ.
Regression xảy ra khi một query hoặc query family:
- trước đây có plan A đủ tốt;
- sau một thay đổi nào đó chuyển sang plan B xấu hơn;
- latency, I/O hoặc CPU tăng mạnh dù business requirement gần như không đổi.
Từ góc production, điều đáng sợ không chỉ là query chậm hơn. Điều đáng sợ là planner xấu thường xuất hiện chọn lọc:
- chỉ với một subset parameter;
- chỉ trên một tenant lớn;
- chỉ sau khi data volume vượt ngưỡng;
- chỉ sau
ANALYZEhoặc autovacuum; - chỉ trên replica hoặc environment có data skew khác.
Vì vậy, kiểu debug “query này ở staging chạy nhanh mà” thường không giúp nhiều.
Những nguồn gây regression phổ biến nhất
1. Statistics stale hoặc statistics quá nghèo
PostgreSQL dựa vào ANALYZE để thu thập statistics cho planner. Nếu statistics cũ, planner có thể ước lượng sai số row match, độ chọn lọc của predicate, hoặc cost của join order.
Nhưng có một nuance quan trọng: statistics không chỉ có thể stale, mà còn có thể đúng theo sample nhưng chưa đủ giàu để mô tả data distribution lệch mạnh.
Ví dụ hay gặp:
- cột
statuscó 95% làdone, 5% làpending, nhưng tenant lớn có phân bố ngược lại; - cột
country,region,citycó tương quan mạnh nhưng planner giả định gần độc lập; - một customer enterprise chiếm phần lớn row của bảng và làm hỏng ước lượng cho
customer_id + created_at.
Trong các case này, chỉ “ANALYZE lại” đôi khi chưa đủ. Vấn đề nằm ở độ giàu của statistics hoặc ở assumption independence.
2. Data skew và parameter-sensitive plan
Một query prepared statement có thể được dùng cho hàng triệu request với parameter khác nhau. Có parameter mà index scan rất hợp lý. Có parameter khác mà sequential scan hoặc bitmap scan lại tốt hơn.
Nếu hệ thống rơi vào tình huống một generic plan được tái sử dụng quá rộng, hoặc planner tạo plan dựa trên expectation trung bình trong khi distribution thực tế rất skew, anh sẽ gặp hiện tượng:
- 90% request ổn;
- 10% request cực chậm;
- nhìn average thì có vẻ không quá tệ, nhưng p95/p99 vỡ mạnh.
Đây là một lý do khiến query plan regression hay bị nhầm thành “application random lag”. Thực tế nó chỉ chậm với vài parameter xấu.
3. Join order hoặc join algorithm đổi theo cardinality estimate sai
Sai ở đầu vào cardinality sẽ kéo theo sai cả chuỗi quyết định:
- planner chọn nested loop thay vì hash join;
- chọn build hash table ở phía quá lớn;
- chọn join order khiến filter chọn lọc cao được áp quá muộn;
- dùng index scan nhiều lần cho outer loop lớn thay vì scan tập trung một lần.
Nhiều incident nhìn ở bề mặt là “nested loop làm mọi thứ chết”, nhưng nested loop không phải kẻ có tội tuyệt đối. Vấn đề gốc là planner tin rằng outer side nhỏ, trong khi thực tế outer side lớn gấp hàng trăm lần estimate.
4. Bloat, correlation thay đổi hoặc physical layout drift
Cùng một index, cùng một query, nhưng hiệu quả có thể đổi khi:
- table/index bloat tăng;
- row ordering lệch xa logical ordering;
- visibility map khác đi, làm index-only scan không còn rẻ như trước;
- cache locality xấu hơn theo thời gian.
Planner có dùng một số thống kê như correlation để ước lượng cost của index scan. Khi physical reality drift đủ xa, plan cũ có thể không còn ngon nữa.
Bởi vậy query plan regression không tách biệt hoàn toàn khỏi các bài toán như MVCC, VACUUM và bloat. Nó thường là hệ quả của chúng.
5. Thay đổi SQL tưởng nhỏ nhưng làm planner mất đường tối ưu
Một refactor “vô hại” ở application layer có thể làm planner nhìn bài toán khác hẳn:
- thêm
ORthay vì tách thành hai nhánh; - wrap cột trong function khiến index khó dùng;
- thêm
ORDER BYhoặcLIMITlàm đổi cost trade-off; - chuyển từ literal sang prepared statement làm thay đổi plan reuse behavior;
- thêm một join lookup nhỏ nhưng làm join order toàn query đổi khác.
Điểm quan trọng là regression không nhất thiết cần schema change. Chỉ cần query shape đổi là đủ.
Đừng bắt đầu bằng “query plan xấu”, hãy bắt đầu bằng triệu chứng production
Khi nghe “plan xấu”, nhiều người mở ngay EXPLAIN ANALYZE trên laptop rồi tranh luận hash join với nested loop. Cách này thường đốt thời gian.
Thứ nên khóa đầu tiên là triệu chứng production:
- query nào hoặc endpoint nào đang xấu;
- xấu từ lúc nào;
- mọi request đều xấu hay chỉ một nhóm parameter;
- regression gắn với deploy, autovacuum/analyze, data backfill hay traffic mix mới;
- latency tăng do CPU, I/O, temp spill, lock wait hay network serialization.
Nếu chưa có framing này, việc đọc plan rất dễ trở thành tranh luận cảm tính.
pg_stat_statements: nơi nên bắt đầu trước khi mở plan detail
Với production PostgreSQL, pg_stat_statements gần như là điểm xuất phát tốt nhất để tìm query family đang thật sự đắt tiền. Nó cho anh:
calls-
mean_exec_time,max_exec_time rows-
shared_blks_hit,shared_blks_read - planning stats nếu bật track planning
Điều giá trị nhất không phải chỉ là “query nào chậm nhất”, mà là tìm pattern:
- query có
max_exec_timecực cao nhưng mean không quá lớn → nghi parameter-sensitive plan; - query có
shared_blks_readtăng mạnh sau một mốc thời gian → nghi planner đổi sang đường đọc tốn I/O hơn; - query có rows trả về nhỏ nhưng block usage lớn → nghi plan đi đường vòng hoặc selectivity estimate sai.
Một nguyên tắc thực chiến: đừng tối ưu bằng một lần chạy local của query cụ thể nếu production aggregate đang kể câu chuyện khác.
Cách đọc EXPLAIN (ANALYZE, BUFFERS) mà không tự lừa mình
Tài liệu PostgreSQL nhấn mạnh rằng EXPLAIN cho biết planner scan table/join thế nào, còn ANALYZE cho actual runtime statistics; BUFFERS cho block hit/read/dirtied/written. Với production debugging, ba lớp này phải đi cùng nhau.
1. So actual rows với estimated rows ở từng node
Đây là cách nhanh nhất để tìm planner đang “tin sai” ở đâu.
Nếu thấy:
- estimate 10 rows, actual 200,000 rows;
- estimate 1 loop, actual loop lồng nhau rất lớn;
- upper node tệ vì lower node underestimate;
thì gốc vấn đề thường là cardinality estimation, không phải đơn giản là “hash join dở” hay “index scan chậm”.
2. Nhìn BUFFERS, không chỉ nhìn total time
Có query chậm vì CPU. Có query chậm vì I/O. Có query chậm vì spill temp. BUFFERS giúp phân biệt:
- shared blocks read tăng → plan đang đọc nhiều hơn từ storage/cache miss path;
- shared blocks hit rất cao nhưng total vẫn lớn → có thể CPU-bound hoặc scan quá nhiều data trong cache;
- temp blocks read/write → sort/hash spill, thường liên quan work_mem hoặc join/order strategy.
Nếu không đọc BUFFERS, rất dễ fix nhầm thứ.
3. Cẩn thận với EXPLAIN ANALYZE trên môi trường thật
Tài liệu PostgreSQL cũng cảnh báo rõ: ANALYZE thực thi statement thật. Với INSERT/UPDATE/DELETE, phải cực cẩn thận; muốn test mà không giữ side effect có thể dùng transaction rồi rollback.
Ngay cả với SELECT, cũng đừng quên:
- chạy trên thời điểm hệ thống đang nóng có thể làm nặng thêm cache/IO path;
- một lần chạy tay chưa chắc đại diện cho parameter production đang xấu;
- plan khi copy literal vào session thủ công có thể khác plan prepared statement thực tế.
4. SETTINGS và generic/custom nuance đáng để xem
Khi nghi có session-level config khác thường hoặc planner behavior bị ảnh hưởng bởi setting không mặc định, dùng EXPLAIN với SETTINGS có ích. Nếu nghi prepared statement/generic plan là thủ phạm, phải tách bạch giữa:
- plan khi chạy với literal cụ thể;
- custom plan theo parameter;
- generic plan tái sử dụng.
Nếu không, anh có thể tối ưu nhầm cho bản demo chứ không phải đường chạy thật.
Statistics: phần nhiều team biết là quan trọng, nhưng ít team debug đến nơi
ANALYZE chỉ là bước đầu
Tài liệu PostgreSQL mô tả ANALYZE là cơ chế thu thập statistics vào pg_statistic để planner chọn plan hiệu quả hơn. Nhưng trong production, “chạy ANALYZE” không phải câu trả lời đầy đủ. Cần hỏi thêm:
- statistics hiện tại có stale không;
- sample có đủ tốt không;
- cột nào đang chi phối plan choice;
- có correlation đa cột mà planner không thấy không.
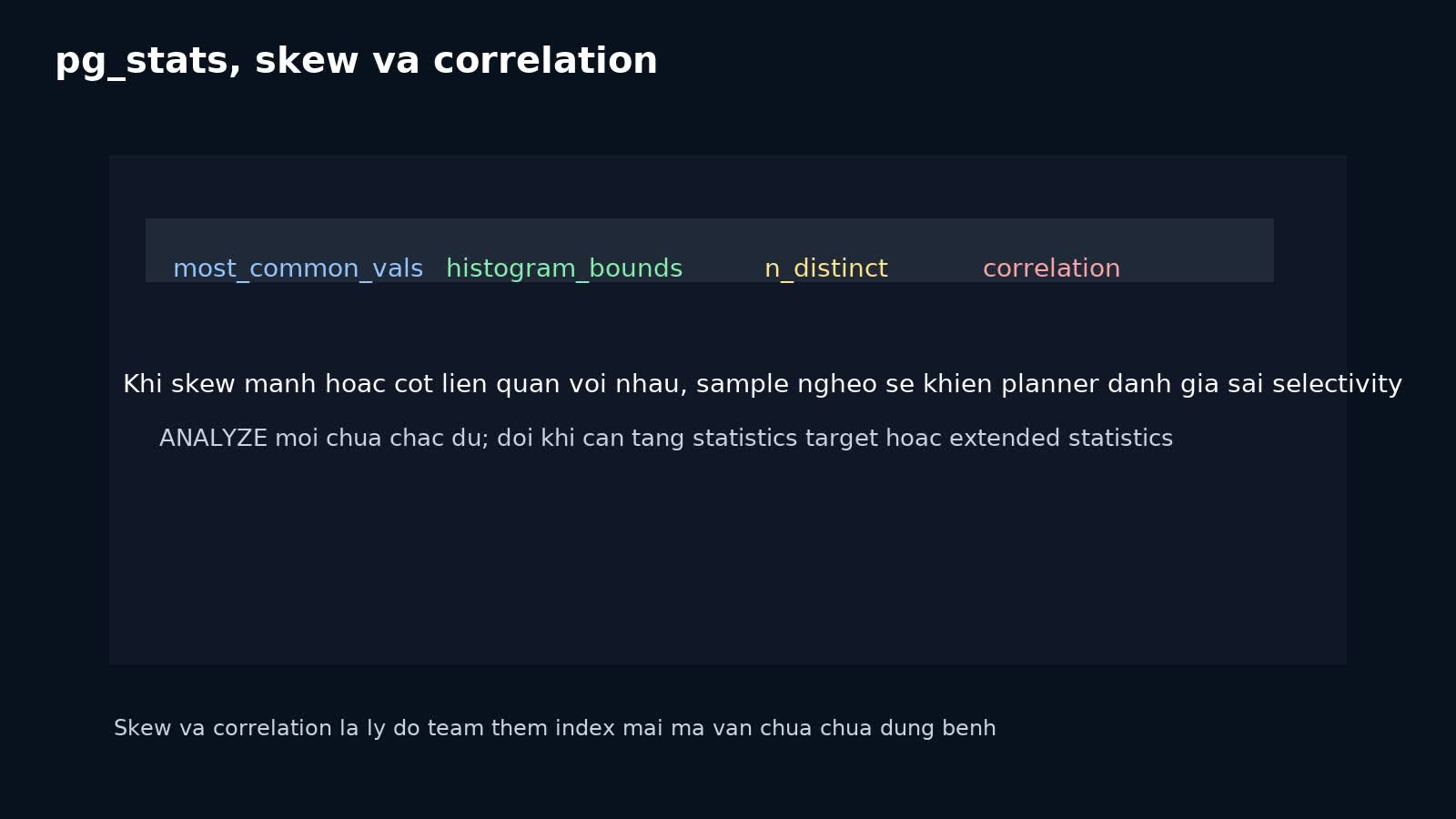
pg_stats cho biết planner đang nhìn dữ liệu thế nào
View pg_stats cho phép đọc thông tin dễ hiểu hơn từ pg_statistic, gồm:
n_distinctmost_common_valsmost_common_freqshistogram_boundscorrelation
Nếu query filter trên cột có phân phối rất lệch, most_common_vals và histogram_bounds thường cho anh manh mối vì sao planner ước lượng sai. Nếu index scan trước đây tốt nhưng giờ random hơn và kém hiệu quả, correlation cũng là một tín hiệu đáng xem.
default_statistics_target không nên tăng bừa toàn cụm
Tài liệu planner stats chỉ ra rằng có thể tăng lượng thông tin statistics toàn cục bằng default_statistics_target, hoặc tăng chọn lọc hơn theo từng cột bằng ALTER TABLE ... SET STATISTICS.
Trong thực tế, cách ít phá hơn là:
- xác định cột nào thực sự gây estimate sai;
- tăng statistics target cho đúng cột đó;
- chạy
ANALYZElại; - so sánh plan trước/sau.
Tăng toàn hệ thống có thể làm ANALYZE nặng hơn, tăng thời gian thu thập, và thường là overshoot nếu chỉ vài cột có distribution khó.
Khi nào nên nghĩ tới extended statistics
Nếu query phụ thuộc vào nhiều cột có tương quan mạnh, single-column statistics thường không đủ. Đây là case kinh điển cho extended statistics:
-
tenant_id+status -
country+region -
customer_id+deleted_at -
type+created_attrong từng partition logic
Nếu planner liên tục sai vì assumption independence, thêm index mới mãi có thể không giải quyết được gốc bệnh. Gốc bệnh là planner không hiểu relationship giữa các cột.
Parameter-sensitive plan: chỗ ORM và prepared statement thường bị oan hoặc bị bỏ sót
Một query chạy nhanh với customer nhỏ nhưng chậm với customer lớn là mùi rất đặc trưng.
Ví dụ tưởng tượng:
SELECT *
FROM invoices
WHERE tenant_id = $1
AND status = 'pending'
ORDER BY created_at DESC
LIMIT 50;Với tenant nhỏ, index (tenant_id, status, created_at) có thể quá ngon.
Với tenant cực lớn mà pending chiếm tỷ lệ cao bất thường, cùng query có thể scan nhiều hơn hẳn dự kiến. Nếu planner chọn generic plan dựa trên trung bình toàn bảng, plan đó có thể đủ ổn cho phần lớn tenant nhưng cực tệ cho tenant lớn nhất — tức khách quan trọng nhất.
Dấu hiệu nhận diện:
- cùng queryid nhưng variance latency cao;
-
max_exec_timelệch xamean_exec_timetrongpg_stat_statements; - chỉ một nhóm account/tenant/report bị than phiền.
Cách nghĩ đúng ở đây không phải “PostgreSQL ngẫu nhiên”. Nó đang tối ưu theo information nó có, nhưng information đó không đại diện cho phân phối của parameter xấu.
Join regression: đừng chỉ blame nested loop
Nested loop thường là người bị ghét đầu tiên vì khi estimate sai, nó tạo blast radius rất đắt. Nhưng nếu chỉ dừng ở việc “tắt nested loop”, anh đang chặn một triệu ca hợp lệ chỉ vì một ca bệnh.
Thay vào đó hãy hỏi:
- Outer relation thực tế lớn hơn estimate bao nhiêu?
- Predicate nào làm cardinality sai?
- Có filter nào bị đẩy xuống quá muộn?
- Có statistics đa cột còn thiếu không?
- Có index nào chỉ làm planner tự tin sai hơn chứ không thật sự giúp execution không?
Có những case hash join đúng là tốt hơn, nhưng root cause vẫn là estimate sai. Nếu estimate không sửa, query khác sẽ lại ngã.
Những anti-pattern fix rất hấp dẫn nhưng dễ trả giá đắt
1. Tắt planner feature ở cấp global
Ví dụ:
enable_nestloop = offenable_seqscan = offenable_hashjoin = off
Tài liệu PostgreSQL coi đây là công cụ crude để influence plan, chủ yếu cho chẩn đoán hoặc tạm thời. Nếu dùng như fix hệ thống, anh đang can thiệp mù lên optimizer cho toàn workload.
2. Thêm index chỉ để “ép” một plan
Index mới đôi khi đúng. Nhưng nếu thêm index mà không hiểu query xấu vì selectivity estimate sai hay vì join order sai, anh có thể:
- tăng write amplification;
- tăng bloat/index maintenance;
- khiến planner có thêm nhiều đường sai hơn;
- giữ root cause còn nguyên.
3. Chạy VACUUM FULL hoặc restart như nghi thức chữa cháy
Có case bloat hoặc cache reset làm triệu chứng đỡ tạm thời, nhưng nếu regression do statistics/correlation/generic plan, cách này chỉ đổi hình thức chậm chứ không sửa logic chọn plan.
Một playbook thực chiến để debug query plan regression
Bước 1: xác định query family đang xấu bằng pg_stat_statements
Tìm queryid hoặc normalized query có:
- tăng
mean_exec_time,p95/p99ở APM nếu có; -
max_exec_timespike; -
shared_blks_readhoặc temp IO bất thường.
Bước 2: khoanh mốc thời gian và sự kiện đi kèm
Hỏi thẳng:
- vừa deploy SQL/application gì?
- vừa có backfill/import lớn?
- vừa chạy
ANALYZE, autovacuum mạnh, reindex? - traffic mix có tenant mới/campaign/report mới không?
Bước 3: lấy plan đại diện cho parameter tốt và parameter xấu
Nếu nghi parameter-sensitive, phải so sánh ít nhất hai case. Một plan “đẹp” cho tenant nhỏ không đại diện cho tenant lớn.
Bước 4: đọc chênh lệch estimate vs actual
Tập trung vào node đầu tiên nơi estimate bắt đầu sai lớn. Phần còn lại thường chỉ là hậu quả dây chuyền.
Bước 5: kiểm tra statistics liên quan trong pg_stats
Nhìn n_distinct, most_common_vals, histogram_bounds, correlation. Nếu query dựa trên nhiều cột liên quan chặt, đánh giá luôn khả năng cần extended statistics.
Bước 6: xác định loại fix nhỏ nhất có ý nghĩa
Theo thứ tự thường nên cân nhắc:
-
ANALYZElại đúng bảng/cột khi stats stale. - Tăng statistics target cho vài cột then chốt.
- Thêm extended statistics cho cặp/nhóm cột correlated.
- Sửa query shape để predicate/index-friendlier hơn.
- Thêm/chỉnh index nếu execution path thật sự thiếu access path tốt.
- Chỉ dùng planner GUC như công cụ chẩn đoán hoặc tạm thời cực ngắn hạn.
Ví dụ mental model: query chậm hơn sau ANALYZE không có nghĩa ANALYZE “làm hỏng database”
Đây là hiểu nhầm khá phổ biến. ANALYZE chỉ làm planner có thêm thông tin. Nếu sau ANALYZE plan tệ hơn, thường có vài khả năng:
- statistics mới phản ánh dữ liệu thật hơn, và data shape hiện tại khiến đường cũ không còn rẻ;
- sample mới lộ ra skew mà planner diễn giải theo cost model hiện tại;
- query đang phụ thuộc vào một plan may mắn cũ chứ không phải một thiết kế bền vững.
Nói cách khác, ANALYZE không phải “phản bội” anh. Nó thường chỉ phơi ra vấn đề mà trước đó tình cờ bị che đi.
Khi nào bài toán không còn là planner nữa mà là thiết kế dữ liệu
Có những lúc plan regression là tín hiệu cho thấy model dữ liệu hoặc access pattern đã vượt quá phạm vi tối ưu nhỏ lẻ.
Ví dụ:
- multi-tenant table quá skew nhưng vẫn dùng một access path chung;
- bảng event/log quá lớn nhưng không partition hoặc archive hợp lý;
- query dashboard cố ép OLTP schema làm OLAP lite;
- soft delete khiến data “active” nhỏ nhưng planner phải nhìn tổng bảng khổng lồ.
Khi đó, fix đúng có thể là:
- partitioning;
- partial index;
- summary/materialized layer;
- archival strategy;
- tách hot/cold path.
Nếu cứ coi mọi regression là “cần thêm 1 index”, anh sẽ chỉ kéo technical debt database đi xa hơn.
Checklist production để tránh query plan regression tái diễn
- Bật và theo dõi
pg_stat_statementstử tế. - Khi có query quan trọng, lưu baseline
EXPLAIN (ANALYZE, BUFFERS)cho case tiêu biểu. - Review prepared statement/query builder ở những luồng có data skew mạnh.
- Tăng statistics target theo cột trọng điểm thay vì mặc định hóa cả cluster.
- Dùng extended statistics cho predicate nhiều cột có correlation thật.
- Theo dõi bloat, autovacuum, long transaction vì chúng ảnh hưởng gián tiếp lên plan quality.
- Không dùng planner GUC global như giải pháp đầu tiên.
- Với tenant/report cực lớn, kiểm tra xem workload đó có cần đường truy cập riêng không.
Internal links nên đọc tiếp
- Nếu query chậm dần theo thời gian vì dead tuples và bloat, xem thêm bài PostgreSQL MVCC, VACUUM và table bloat tại
/postgresql-mvcc-vacuum-bloat-production/. - Nếu bottleneck gốc là truy cập dữ liệu sai hướng, xem thêm Index trong PostgreSQL: cách tối ưu query performance cho backend production tại
/postgresql-index-query-performance/. - Nếu hệ thống đang chịu tải cao và query xấu làm hàng đợi downstream phình ra, xem thêm Queue-Based Load Leveling trong Backend Production tại
/queue-based-load-leveling-backend-production/. - Nếu application layer cố bù cho DB bằng retry vô tội vạ, xem thêm Backpressure và Load Shedding trong Backend tại
/backend-backpressure-load-shedding/. - Nếu nghiệp vụ dựa vào replica và có triệu chứng stale read lẫn plan confusion khi so sánh môi trường, xem thêm Read-after-write consistency trong production tại
/read-after-write-consistency-replica-lag-production/. - Nếu join/report path quá lệ thuộc contract giữa service và DB-facing schema, xem thêm Contract Testing cho Microservices tại
/contract-testing-microservices-production/để giữ thay đổi bớt phá ngầm ở tầng truy vấn.
Kết luận
PostgreSQL query plan regression production không phải một bug huyền bí của database. Nó thường là giao điểm của ba thứ: planner estimate, data distribution thực tế, và query shape/application behavior. Nếu chỉ nhìn plan cuối cùng rồi chọn phe hash join hay nested loop, anh rất dễ bỏ lỡ node đầu tiên nơi planner bắt đầu tin sai.
Cách debug bền vững hơn là đi từ triệu chứng production → pg_stat_statements → EXPLAIN (ANALYZE, BUFFERS) → pg_stats → loại fix nhỏ nhất có ý nghĩa. Có lúc chỉ cần ANALYZE và tăng statistics target cho vài cột. Có lúc cần extended statistics. Có lúc phải sửa query hoặc access pattern. Và cũng có lúc regression chỉ là tín hiệu rằng data model hiện tại đã tới ngưỡng cần tái thiết kế.
Điểm quan trọng nhất: đừng ép planner mù quáng trước khi hiểu vì sao nó chọn plan đó. Khi hiểu được nguyên nhân estimate lệch, phần lớn fix sẽ nhỏ hơn anh tưởng, và ít để lại debt hơn nhiều so với việc rải planner hacks khắp hệ thống.