Adaptive Concurrency Limits trong Backend Production: giữ latency ổn định mà không chờ hệ thống sập mới throttle
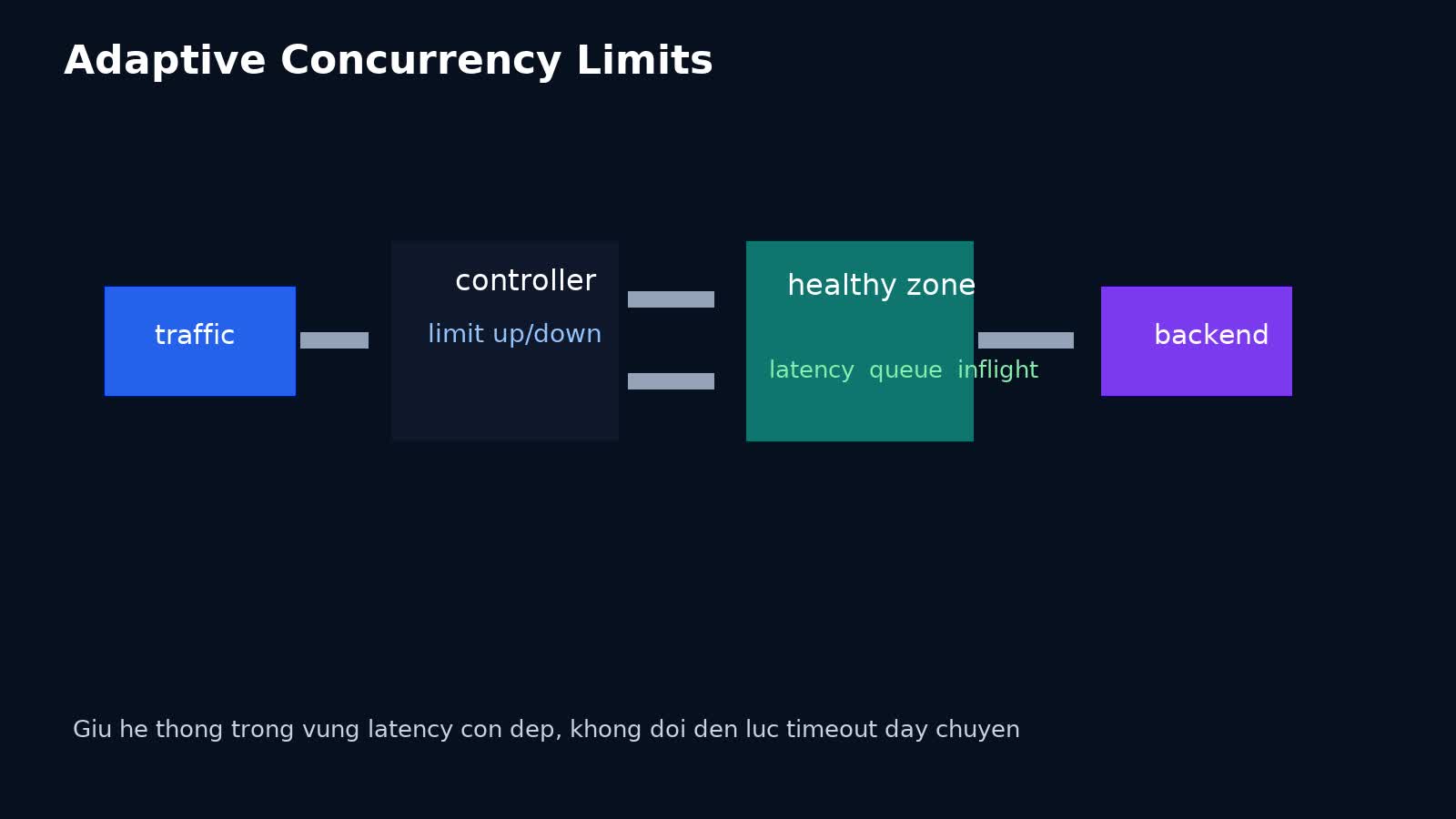
Adaptive concurrency limits là một trong những kỹ thuật rất đáng giá nhưng lại thường bị nói qua loa trong các cuộc thảo luận về reliability. Nhiều team biết rate limiting, biết circuit breaker, biết autoscaling, nhưng khi hệ thống bắt đầu chậm dần do số request in-flight tăng quá cao, họ vẫn phản ứng hơi muộn: hoặc để traffic tràn vào cho đến lúc timeout dây chuyền, hoặc cắt quá mạnh khiến throughput tụt vô ích.
Vấn đề nằm ở chỗ nhiều failure mode trong production không đến từ lỗi hẳn, mà đến từ độ đồng thời vượt quá điểm hệ thống còn xử lý hiệu quả. CPU chưa chắc đã 100%. Database chưa chắc đã down. Nhưng queue length tăng, tail latency phình ra, connection pool căng hơn, GC pause khó chịu hơn, và upstream bắt đầu retry theo cách làm mọi thứ tệ thêm. Đây là lúc adaptive concurrency limits đáng xuất hiện.
Kỹ thuật này không cố đoán trước một con số concurrency “đúng mãi mãi”. Nó dùng tín hiệu runtime như latency, inflight requests, queueing, hoặc success sample để điều chỉnh ngưỡng concurrency động theo trạng thái thật của dependency hay service. Nói dễ hiểu: thay vì để hệ thống ngộp rồi mới timeout, ta chủ động giữ số request đang cùng tranh tài nguyên ở vùng mà service còn phản hồi tử tế.
Bài này đi thẳng vào mặt production: adaptive concurrency limits giải bài toán gì, khác gì rate limiting và circuit breaker, chọn tín hiệu điều khiển thế nào, đặt limit ở layer nào, rollout ra sao, các anti-pattern phổ biến, và vì sao nhiều hệ thống fail không phải vì thiếu autoscaling mà vì thiếu kỷ luật concurrency ở critical path.
Adaptive concurrency limits thực chất giải bài toán gì?
Nó giải bài toán saturation trước khi saturation biến thành failure rõ ràng.
Nhiều service không gãy ngay khi load tăng. Thay vào đó, chúng đi qua một vùng xấu dần:
- số request đồng thời tăng;
- contention trên CPU, lock, thread pool, DB pool hoặc event loop tăng;
- latency tăng theo cách phi tuyến;
- queue age tăng;
- timeout bắt đầu xuất hiện muộn ở upstream;
- retry amplification làm downstream còn mệt hơn.
Nếu cứ tiếp tục nhận request với cùng nhịp, hệ thống có thể rơi vào trạng thái throughput không tăng thêm bao nhiêu nhưng latency và error rate tăng rất mạnh. Đây chính là vùng mà concurrency limit nên chặn lại.
Điểm quan trọng là: mục tiêu không phải giảm load về zero, mà giữ hệ thống quanh vùng hiệu quả nhất giữa throughput và latency.
Vì sao fixed concurrency limit thường không đủ?
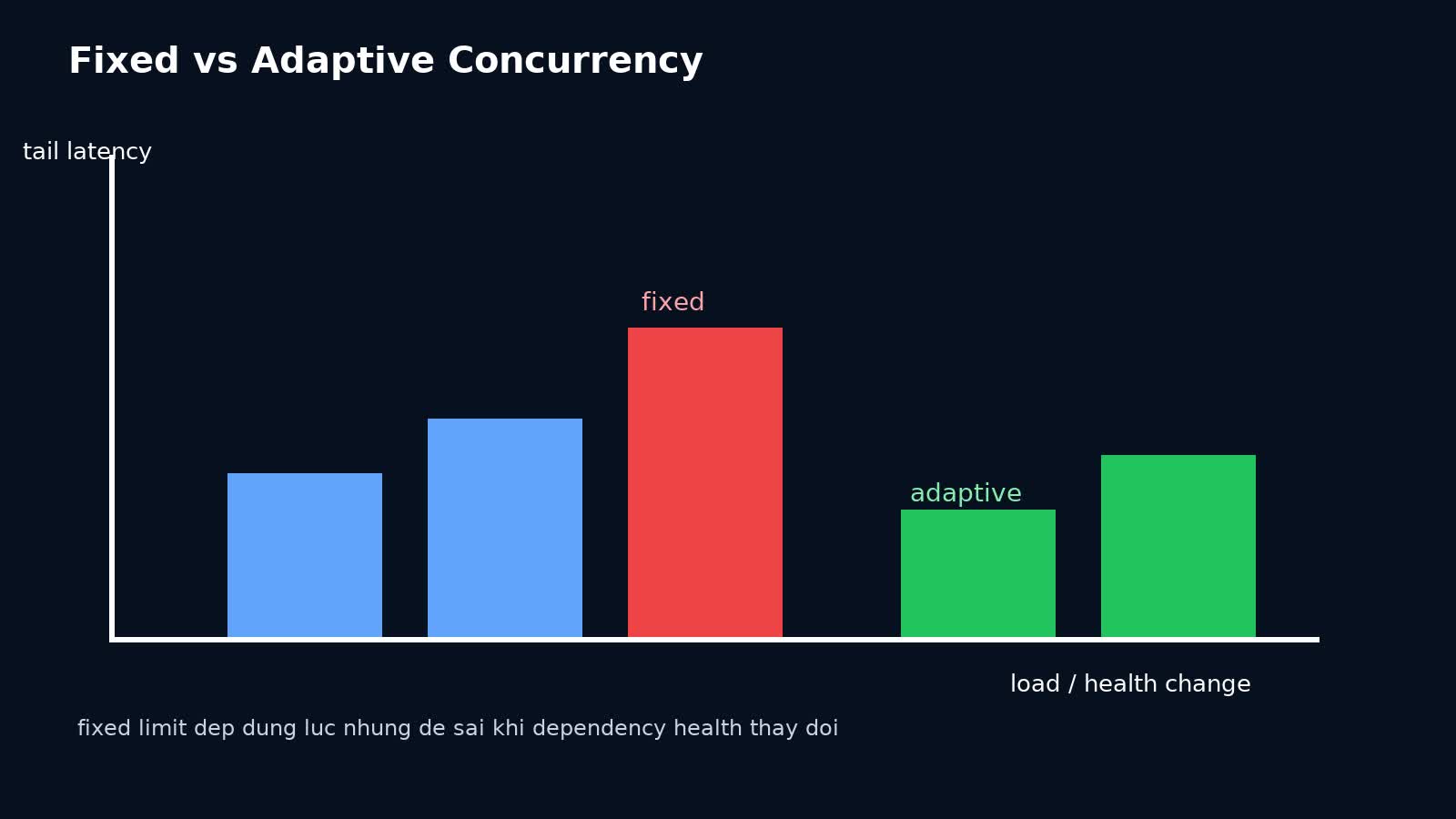
Fixed limit vẫn hữu ích, nhưng nó có ba vấn đề lớn trong production thật.
1. Tải hệ thống thay đổi theo thời gian
Một ngưỡng 200 concurrent requests có thể ổn vào buổi sáng, nhưng thành quá hung hãn khi:
- node noisy hơn bình thường;
- cache hit rate giảm;
- downstream database đang chậm nhẹ;
- GC behavior thay đổi sau deploy;
- một zone bị degraded.
Ngược lại, cùng limit đó có thể lại quá bảo thủ khi traffic nhẹ và dependency đang rất khỏe.
2. Mỗi endpoint có profile tài nguyên khác nhau
Một API read từ cache và một API fan-out tới 4 service + database không nên chịu cùng một concurrency budget theo kiểu copy-paste.
3. Dependency health thay đổi liên tục
Nút thắt có thể không nằm ở service của anh, mà nằm ở downstream. Khi dependency đó bắt đầu chậm, concurrency “an toàn” cũng giảm theo. Fixed limit không phản ánh điều này nếu không có tuning thủ công liên tục.
Adaptive limit tồn tại vì production không đứng yên.
Adaptive concurrency khác gì rate limiting?
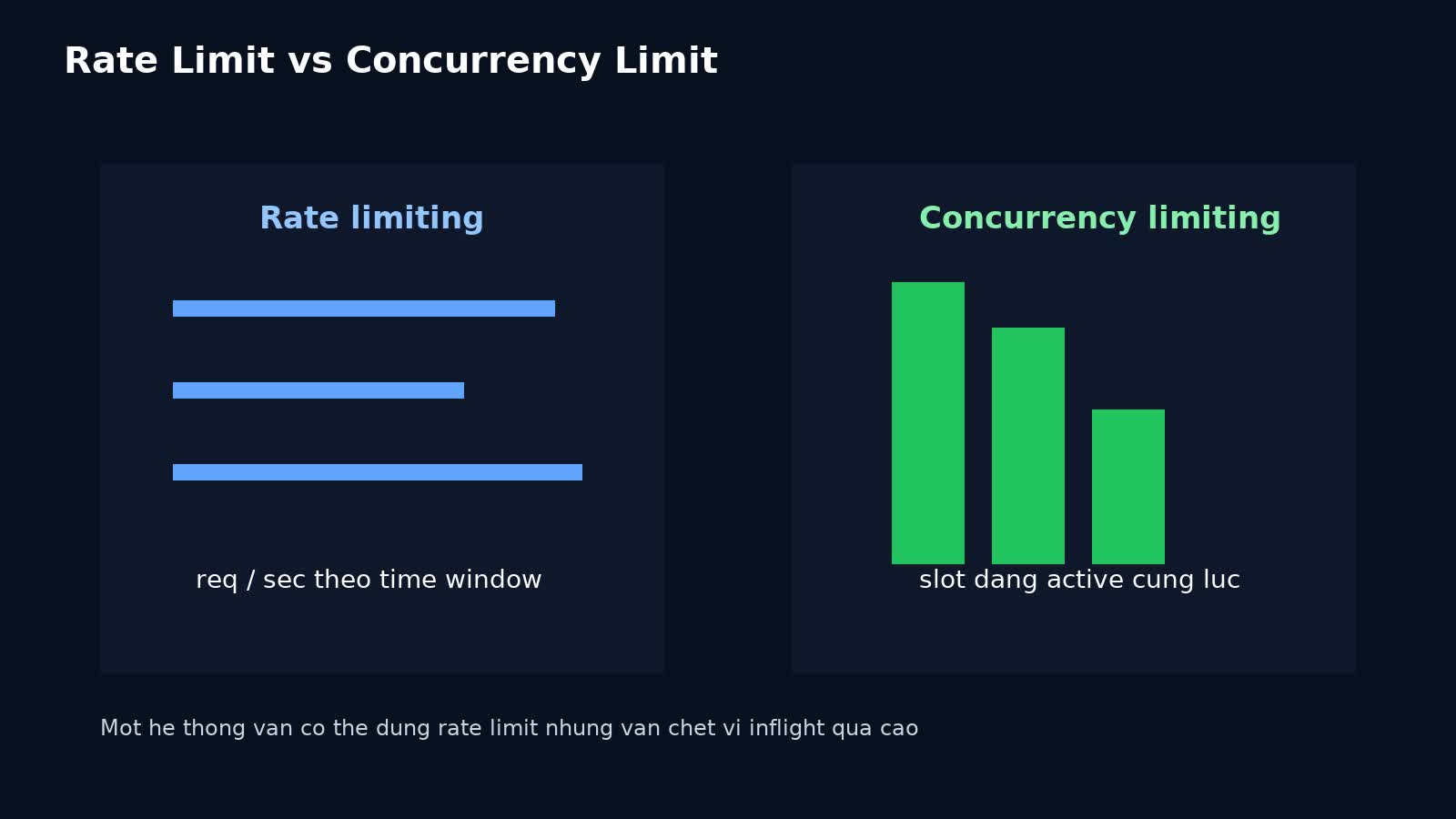
Đây là chỗ nhiều team nhầm.
Rate limiting
Rate limiting kiểm soát tốc độ request theo thời gian, ví dụ 1000 request/phút hoặc 200 request/giây. Nó phù hợp để:
- chống abuse;
- phân bổ fairness giữa tenant/client;
- bảo vệ API public;
- giữ budget traffic tổng thể.
Concurrency limiting
Concurrency limiting kiểm soát số request đang active cùng lúc. Nó phù hợp để:
- bảo vệ thread pool / worker pool / connection pool;
- giảm queueing delay;
- giữ tail latency khỏi bùng lên;
- tránh hệ thống tự nghẹt khi dependency chậm.
Một hệ thống có thể tuân thủ rate limit nhưng vẫn chết vì concurrency quá cao nếu request nào cũng kéo dài lâu hơn bình thường.
Nói ngắn gọn:
- rate limit trả lời: “bao nhiêu request đi vào mỗi đơn vị thời gian?”
- concurrency limit trả lời: “bao nhiêu request đang cùng chiếm tài nguyên ngay lúc này?”
Với production engineering, hai thứ này thường nên đi cùng nhau chứ không thay thế nhau.
Adaptive concurrency khác gì circuit breaker?
Circuit breaker là cơ chế fail-fast khi dependency đang unhealthy. Nó thường phản ứng mạnh hơn: nếu tỷ lệ lỗi hoặc timeout vượt ngưỡng, breaker mở và chặn bớt hoặc chặn hẳn traffic một thời gian.
Adaptive concurrency limits mềm hơn. Nó cố giữ hệ thống trong vùng ổn định trước khi tới mức breaker phải mở.
Có thể hình dung:
- adaptive concurrency = chân ga và chân phanh tinh chỉnh theo mặt đường;
- circuit breaker = rào chắn khẩn cấp khi đoạn đường phía trước quá nguy hiểm.
Nếu dùng đúng:
- adaptive limit giúp giảm xác suất breaker phải mở;
- breaker bảo vệ hệ thống khi adaptive limit không còn đủ, hoặc khi dependency đang fail diện rộng.
Dấu hiệu cho thấy hệ thống cần adaptive concurrency limits
Không phải service nào cũng cần ngay, nhưng các dấu hiệu dưới đây rất đáng chú ý:
1. Tail latency tăng rất nhanh khi traffic tăng vừa phải
P50 còn đẹp nhưng P95/P99 bùng lên chỉ vì thêm một ít concurrent work. Đây thường là dấu hiệu queueing và contention, không chỉ là “máy hơi bận”.
2. Throughput gần như không tăng thêm dù inflight tăng mạnh
Nếu số request đồng thời tăng gấp đôi nhưng số request hoàn thành/giây không tăng đáng kể, anh đang đẩy hệ thống vào vùng lãng phí.
3. Timeouts đến từ chờ tài nguyên nhiều hơn từ compute thật
Ví dụ:
- chờ connection pool;
- chờ thread worker;
- chờ queue drain;
- chờ lock;
- chờ downstream slot.
4. Retry storm hoặc fan-out làm incident phình nhanh
Khi một dependency chậm đi, concurrency ở upstream thường tăng theo vì request sống lâu hơn. Nếu upstream lại retry, incident leo thang rất nhanh.
5. Autoscaling có nhưng latency vẫn xấu trước khi node mới kịp cứu
Autoscaling thường phản ứng theo seconds hoặc minutes. Concurrency control phản ứng ngay trong path xử lý request.
Đặt adaptive concurrency limit ở đâu?
Đây là quyết định kiến trúc rất quan trọng.
1. Ở ingress/gateway
Ưu điểm:
- bảo vệ entry point chung;
- dễ triển khai tập trung;
- hữu ích khi nhiều upstream cùng đổ vào một service.
Nhược điểm:
- ít hiểu đặc thù từng route;
- dễ làm một route nặng ảnh hưởng route nhẹ nếu budget không tách riêng.
2. Ở client-side gọi dependency
Đây là vị trí rất mạnh khi service A gọi service B, hoặc gọi database/search/cache cluster thông qua client library có observability tốt.
Ưu điểm:
- phản ánh đúng health của dependency;
- có thể tách limit theo endpoint hoặc per-dependency;
- chặn amplification trước khi đè downstream.
Nhược điểm:
- cần instrumentation tốt;
- có thể tạo policy rời rạc giữa nhiều caller nếu không chuẩn hóa.
3. Ở worker / queue consumer
Rất hợp cho background jobs, batch processors, ingestion pipeline.
Ưu điểm:
- dễ nhìn thấy mối quan hệ giữa concurrency và downstream saturation;
- tránh backfill job hút sạch DB pool hoặc API quota.
Nhược điểm:
- không tự bảo vệ HTTP request path nếu chỉ áp dụng ở queue.
Trong thực tế, approach tốt thường là:
- concurrency limit cơ bản ở ingress;
- adaptive limit sâu hơn ở dependency client hoặc worker class quan trọng;
- quota riêng cho background và request path.
Tín hiệu nào nên dùng để điều chỉnh limit?

Adaptive control chỉ tốt khi nó nghe đúng tín hiệu. Chọn sai tín hiệu thì nó sẽ chase noise.
1. Latency sample
Đây là tín hiệu phổ biến nhất. Nếu observed latency tăng lên vượt vùng mục tiêu, hệ thống giảm concurrency limit. Nếu latency ổn và throughput còn dư, limit có thể tăng dần.
Ưu điểm:
- phản ánh trực tiếp user-visible impact;
- dễ reason;
- phù hợp cho dependency RPC/HTTP.
Nhược điểm:
- dễ bị nhiễu nếu sample quá ngắn;
- phải cẩn thận với outlier và warm-up effect.
2. Queueing / waiting time
Nếu request spend quá nhiều thời gian chỉ để chờ tài nguyên, đó là tín hiệu rất tốt cho saturation.
Ví dụ:
- acquire wait time của DB pool;
- thread pool queue age;
- event loop lag;
- consumer lag trong queue pipeline.
3. Success + inflight + completion rate
Một số algorithm không nhìn trực tiếp CPU hay queue mà quan sát:
- inflight requests hiện tại;
- round-trip time;
- throughput hoàn thành;
- gradient cải thiện hay xấu đi khi tăng/giảm limit.
Đây là kiểu approach gần với các adaptive controllers nổi tiếng trong service mesh / client libraries.
4. Error/timeout signals
Nên dùng như tín hiệu guardrail hơn là tín hiệu chính. Nếu đợi error rate tăng rồi mới giảm concurrency thì thường đã hơi muộn.
Đừng lấy CPU làm tín hiệu duy nhất
CPU hữu ích, nhưng nếu chỉ điều khiển theo CPU thì anh rất dễ trượt bài toán.
Ví dụ:
- DB pool có thể cạn dù CPU app chưa cao;
- queue có thể dài ra vì downstream chậm chứ không vì app thiếu CPU;
- lock contention hoặc network jitter có thể làm latency nổ mà CPU không đổi nhiều.
Adaptive concurrency tốt thường gắn với service time và queueing behavior, không chỉ host utilization.
Cơ chế tăng/giảm limit nên như thế nào?
Nếu controller thay đổi quá nhanh, nó sẽ dao động mạnh. Nếu thay đổi quá chậm, nó mất ý nghĩa.
Một pattern thực dụng:
- tăng limit từ từ khi latency ổn và queue ngắn;
- giảm limit nhanh hơn khi latency vượt ngưỡng hoặc queueing tăng rõ;
- có min/max bounds để tránh drift vô lý;
- có smoothing window để không chase từng spike nhỏ.
Cách nghĩ này giống nhiều control loop production khác: increase conservatively, cut aggressively when danger is real.
Tránh “sawtooth oscillation”
Một anti-pattern phổ biến là limit tăng rồi giảm liên tục như răng cưa vì controller quá nhạy. Hệ quả:
- metrics khó đọc;
- throughput không ổn định;
- caller nhận 429/503 theo kiểu giật cục;
- incident analysis rất mệt.
Để giảm oscillation:
- dùng moving window hợp lý;
- tách fast path guardrail khỏi slow path tuning;
- thêm hysteresis giữa ngưỡng tăng và giảm;
- tránh để một sample outlier quyết định cả control loop.
Adaptive concurrency hoạt động thế nào với fan-out architecture?

Đây là nơi nó đặc biệt đáng giá.
Nếu một request upstream gọi 5 dependency, chỉ cần một dependency bắt đầu chậm là:
- request lifetime tăng;
- inflight ở upstream tăng;
- resource retention tăng;
- concurrency pressure lan ngược lại caller.
Nếu mỗi hop đều “cố phục vụ hết mức có thể” mà không có concurrency discipline, toàn chuỗi dễ rơi vào failure cascade.
Adaptive concurrency ở per-dependency client giúp:
- chặn caller đè quá nhiều request vào dependency đang xấu;
- buộc upstream fail-fast sớm hơn;
- mở đường cho fallback, degrade hoặc partial response;
- giảm retry amplification.
Điều này rất hợp khi kết hợp với các bài như:
- circuit breaker;
- backpressure và load shedding;
- hedged requests;
- SLI/SLO và burn-rate alert.
Khi nào nên trả 429, 503 hay queue tiếp?
Không có một câu trả lời duy nhất. Nó tùy semantics của endpoint.
Trả fail-fast khi
- request không đáng chờ lâu;
- caller có thể retry đúng cách sau backoff;
- hệ thống đã có degrade path;
- queueing thêm chỉ làm latency vô nghĩa.
Queue ngắn có giới hạn khi
- công việc ngắn và variance thấp;
- queue cho phép hấp thụ burst nhỏ;
- caller thật sự benefit từ chờ rất ngắn.
Tránh queue vô tận
Queue không phải nơi cất giấu saturation. Queue dài thường chỉ đổi lỗi “rejected now” thành lỗi “timeout later”. Với user-facing traffic, fail-fast tử tế thường tốt hơn chết chậm.
Quan hệ giữa adaptive concurrency và autoscaling
Tôi khá dị ứng với ý nghĩ “đã có autoscaling thì không cần concurrency limits”. Hai thứ này xử lý hai time scale khác nhau.
Autoscaling
- phản ứng chậm hơn;
- thêm capacity ở tầng node/pod/instance;
- tốt cho sustained load change.
Adaptive concurrency
- phản ứng gần như ngay lập tức;
- giữ service sống qua burst hoặc dependency degradation;
- tốt cho short-term stability trong request path.
Autoscaling mà không có concurrency discipline giống như gọi thêm bàn trong nhà hàng khi bếp đã nghẹt ticket. Có thể giúp phần nào, nhưng không sửa việc khu bếp đang nhận quá nhiều món cùng lúc.
Ví dụ thực tế: database chưa sập nhưng API đã chết chậm
Giả sử một API đọc/ghi vào PostgreSQL qua pool 40 connections.
Khi dependency khác chậm nhẹ, mỗi request giữ DB connection lâu hơn bình thường do transaction scope rộng. Traffic không tăng quá mạnh, nhưng:
- inflight HTTP requests tăng từ 120 lên 260;
- acquire wait của DB pool tăng;
- P99 latency tăng từ 300ms lên 2.5s;
- caller timeout và retry nhẹ;
- pool bắt đầu exhaustion.
Nếu chỉ nhìn rate limiting tổng thể, có thể anh chưa thấy vấn đề. Nhưng adaptive concurrency limit trên route hoặc dependency client có thể nhận ra rằng latency/queueing đang tăng và giảm số request cho phép đi song song xuống trước khi toàn hệ thống vào vòng xoáy timeout.
Kết quả mong muốn không phải “phục vụ tất cả”. Kết quả mong muốn là:
- một phần request bị reject/fail-fast có kiểm soát;
- request còn lại hoàn thành nhanh hơn;
- database không bị kéo vào collapse sâu hơn;
- retry storm giảm.
Rollout adaptive concurrency an toàn như thế nào?
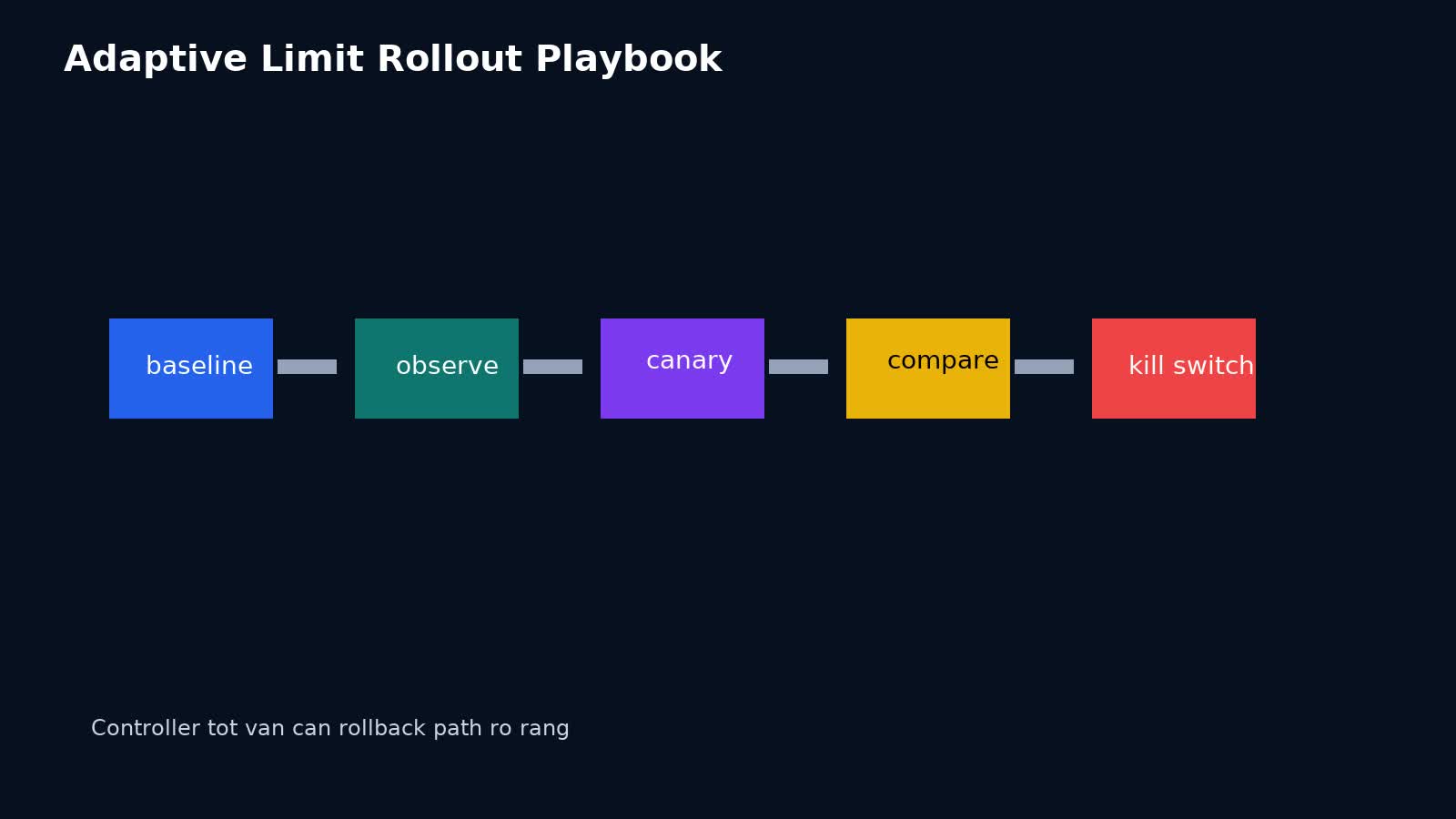
Đừng bật big bang.
Bước 1: chọn một dependency hoặc route đủ quan trọng
Tốt nhất là nơi đã có dấu hiệu tail latency nhạy với inflight concurrency.
Bước 2: đo baseline
Ít nhất phải có:
- inflight requests;
- completion rate;
- P50/P95/P99 latency;
- queue/acquire wait;
- reject count;
- downstream saturation signals;
- retry rate ở upstream nếu có.
Bước 3: bật observe-only hoặc shadow recommendation nếu hệ thống hỗ trợ
Cho controller tính limit đề xuất nhưng chưa enforce, để xem nó sẽ phản ứng ra sao.
Bước 4: enforce trên một phần traffic nhỏ
Ví dụ 5–10% route hoặc một canary instance.
Bước 5: so sánh trade-off
Cần hỏi rất thẳng:
- P99 có giảm đủ đáng không?
- reject rate tăng bao nhiêu?
- throughput thực tế giảm hay ổn hơn?
- downstream có bớt saturation không?
- retry amplification có giảm không?
Bước 6: chuẩn bị kill switch
Nếu controller hành xử không ổn, phải tắt rất nhanh được.
Metrics bắt buộc phải có
Muốn adaptive concurrency không trở thành “ma thuật khó hiểu”, tối thiểu nên đo:
- current concurrency limit;
- inflight requests hiện tại;
- request admitted count;
- request rejected count;
- latency before/after enforcement;
- queue wait/acquire wait;
- limit increase events;
- limit decrease events;
- retry rate upstream;
- fallback/degrade activation rate nếu có.
Nếu làm tracing tốt hơn, mỗi span nên cho thấy:
- request bị admit hay reject;
- limit tại thời điểm quyết định;
- dependency/route nào áp limit;
- reject do hard cap hay adaptive cap;
- retry attempt number nếu request đến từ caller có retry.
Adaptive concurrency rất cần semantic segregation
Đây là điểm tôi thấy nhiều hệ thống làm chưa tốt.
Không nên cho mọi loại traffic tranh cùng một limit nếu semantics rất khác nhau, ví dụ:
- request interactive của user;
- webhook processing;
- batch backfill;
- admin export nặng;
- health/metadata endpoints.
Nếu không tách lane, batch job rất dễ ăn hết budget của traffic quan trọng hơn.
Các cách tách thường gặp:
- per-route limit;
- per-priority-class limit;
- per-tenant class;
- tách request path và background worker pool;
- reserved concurrency cho traffic critical.
Adaptive controller giỏi đến mấy cũng không cứu được policy segmentation tệ.
Khi nào adaptive concurrency không phải lựa chọn đầu tiên?
Có vài tình huống tôi sẽ sửa gốc trước.
1. Một query hoặc lock path rõ ràng đang hỏng
Nếu root cause là một query plan regression hay transaction giữ lock quá lâu, sửa gốc vẫn quan trọng hơn điều tiết concurrency.
2. Timeout budget và retry policy đang hỗn loạn
Nếu caller retry bừa, deadline không rõ, circuit breaker không có, thì adaptive limit sẽ chỉ là thêm một lớp phản ứng vào một hệ vốn đã rối.
3. Không có observability đủ sâu
Nếu anh không đo được inflight, reject, latency, queue wait và downstream saturation, rollout adaptive controller là khá liều.
4. Workload chủ yếu là offline batch có schedule rõ
Một job batch nhiều khi chỉ cần concurrency cap tĩnh + queue discipline là đủ, chưa chắc cần controller động phức tạp.
Anti-pattern phổ biến
1. Dùng một limit cho toàn service
Service nào cũng có hot path và cold path. Một budget chung dễ tạo unfairness.
2. Tăng limit khi CPU còn thấp mà bỏ qua queue wait
Đây là cách tự tin nhưng sai. CPU thấp không có nghĩa downstream hay lock contention đang ổn.
3. Reject mà không có semantics rõ cho caller
Nếu client không biết phân biệt retryable overload với lỗi logic, nó sẽ retry bừa.
4. Adaptive limit nhưng không ràng retry budget
Limiter giảm load ở một hop, nhưng upstream retry vô tổ chức sẽ đẩy load quay lại.
5. Xem reject rate là thất bại tuyệt đối
Trong overload thật, một ít reject có kiểm soát thường tốt hơn để toàn bộ request chậm và timeout. Production engineering không tối ưu cho cảm giác đẹp trên một metric đơn lẻ.
Internal link opportunities trong cluster softwareengineer.vn
- Khi nói về fail-fast với dependency unhealthy diện rộng, nối sang
/circuit-breaker-backend-production/. - Khi nói về saturation thay vì variance, nối sang
/backend-backpressure-load-shedding/. - Khi nói về retry amplification và latency budget, nối sang
/sli-slo-error-budget-production/. - Khi nói về tail latency reduction bằng request racing, nối sang
/hedged-requests-tail-latency-backend-production/để làm rõ khi nào nên hedge, khi nào nên giảm concurrency. - Khi nói về DB pool contention, nối sang
/connection-leak-pool-exhaustion-backend-production/. - Khi nói về replica/read-path degradation, nối sang
/read-after-write-consistency-replica-lag-production/.
Kết luận
Adaptive concurrency limits không phải món đồ chơi tối ưu hóa vi mô. Nó là một guardrail rất thực dụng cho những hệ thống mà overload không đến như một cú sập đột ngột, mà đến như một quá trình nghẹt dần: inflight tăng, queue dài ra, latency phình lên, timeout và retry bắt đầu kéo nhau đi xuống dốc.
Làm đúng, kỹ thuật này giúp team giữ được nhiều request thành công hơn trong vùng hệ thống còn khỏe, thay vì cố ôm tất cả rồi để mọi thứ chậm và vỡ đồng loạt. Làm sai, nó biến thành một controller dao động liên tục, reject khó hiểu, hoặc một lớp che phủ khiến team quên sửa root cause thật.
Nếu phải chốt trong một câu, tôi sẽ chốt thế này: adaptive concurrency limits là cách dạy hệ thống biết nói “đủ rồi” đúng lúc, trước khi production buộc nó phải nói câu đó bằng timeout hàng loạt.