Retry Storm và Timeout Budget trong Backend Production: chặn khuếch đại lỗi trước khi tự DDoS chính mình

> Primary keyword: retry storm timeout budget backend production
> Canonical: https://softwareengineer.vn/retry-storm-timeout-budget-backend-production/
> Category slugs: backend-engineering, system-design-software-architecture, devops-production-engineering
Retry là một cơ chế cứu hệ thống khỏi lỗi tạm thời. Nhưng trong production, retry cũng là một trong những cách nhanh nhất để biến một lỗi nhỏ thành incident diện rộng. Chỉ cần một dependency chậm hơn bình thường vài trăm mili giây, các caller bắt đầu timeout, mỗi tầng retry thêm một lần, queue dài ra, connection pool căng hơn, CPU bận hơn, rồi cả hệ thống tự khuếch đại áp lực lên chính dependency đang yếu. Đó là retry storm.
Điểm nguy hiểm của retry storm là nó thường không bắt đầu từ bug “to”. Nó bắt đầu từ một degradation đủ nhỏ để nhiều dashboard tổng quan chưa báo đỏ ngay:
- một shard database chậm hơn bình thường;
- một upstream API có tỷ lệ timeout nhích lên;
- GC pause dài hơn sau deploy;
- DNS, TLS handshake hoặc network hop tăng latency;
- queue consumer chậm đi nên request giữ resource lâu hơn.
Nếu mỗi tầng đều nghĩ “retry thêm chút nữa chắc ổn”, hệ thống sẽ trả giá bằng hiệu ứng nhân bản traffic đúng lúc tài nguyên đang khan hiếm nhất.
Bài này đi sâu vào retry storm dưới góc nhìn production engineering: vì sao timeout budget quan trọng hơn việc “thêm retry cho chắc”, cách phân bổ deadline qua nhiều tầng call, khi nào nên retry, khi nào nên fail fast, cách phối hợp với circuit breaker, backoff, jitter, idempotency và observability để tránh tự DDoS dependency của mình.
Retry storm là gì và vì sao nó nguy hiểm hơn vẻ ngoài?
Retry storm là hiện tượng lưu lượng tăng đột biến không phải do user traffic thật, mà do hệ thống tự sinh thêm request retry khi một dependency đang chậm hoặc lỗi.
Ví dụ đơn giản:
- service A nhận 100 request/giây từ user;
- A gọi service B;
- B bắt đầu chậm, timeout tăng;
- A retry 2 lần cho mỗi request lỗi;
- gateway hoặc client mobile lại retry thêm 1 lần;
- worker background cũng gọi cùng dependency B.
Chỉ trong vài giây, B không còn chịu 100 request/giây mà có thể phải hứng 200, 300 hoặc hơn — đúng lúc nó đang yếu nhất.
Retry storm nguy hiểm vì:
- nó làm tăng tải lên dependency đang degraded thay vì để dependency có cơ hội hồi phục;
- nó che giấu root cause ban đầu vì dashboard giờ chỉ thấy bão timeout và traffic tăng;
- nó lan qua nhiều tầng: edge, API, worker, queue consumer, webhook sender;
- nó bào mòn timeout budget toàn chuỗi nên request cuối cùng vẫn thất bại, chỉ chậm và tốn tài nguyên hơn.
Timeout budget là gì?
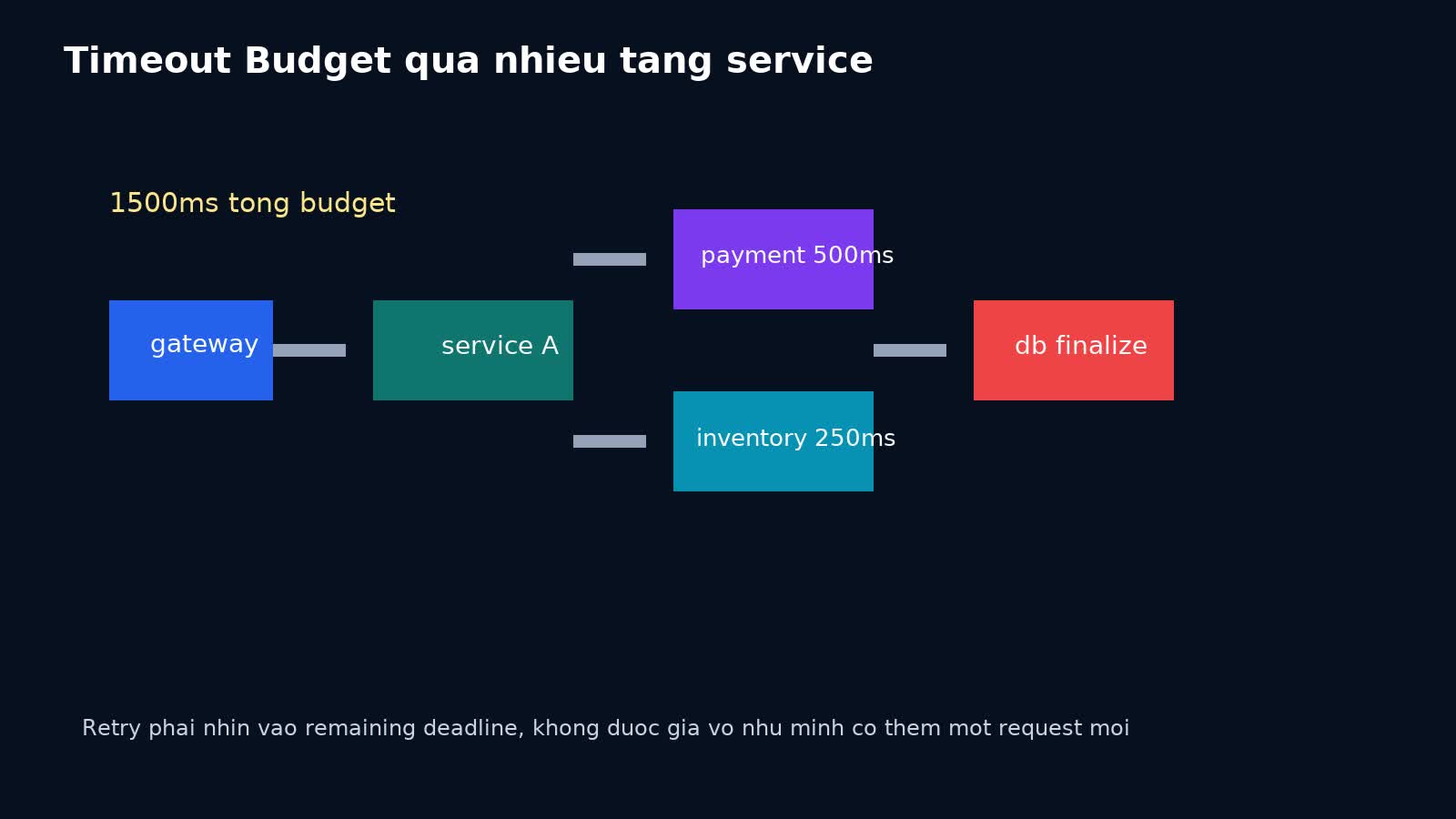
Timeout budget là tổng thời gian tối đa một user-facing operation được phép tiêu tốn trước khi kết quả không còn hữu ích nữa.
Nếu endpoint checkout có SLO nội bộ là phản hồi trong 2 giây, thì 2 giây đó là một dạng budget. Budget này phải được chia cho:
- auth/session lookup;
- business logic chính;
- database query;
- call sang payment, inventory, pricing hoặc fraud service;
- serialization, queue publish, logging/tracing overhead;
- retry nếu thật sự cần.
Sai lầm phổ biến là mỗi tầng tự đặt timeout riêng khá rộng, ví dụ:
- gateway timeout 30s;
- service A gọi B timeout 10s;
- B gọi C timeout 10s;
- C gọi database timeout 5s.
Trên giấy tờ, từng timeout có vẻ “an toàn”. Trong thực tế, tổng ngân sách không còn được kiểm soát. Hệ thống có thể giữ request sống quá lâu, làm inflight tăng, pool cạn, rồi đẩy cả cụm vào congestion.
Vì sao retry không thể tách rời timeout budget?
Retry chỉ hợp lý khi còn đủ thời gian để retry có cơ hội thành công mà không phá hỏng trải nghiệm tổng thể.
Giả sử:
- client kỳ vọng response trong 1500ms;
- lần gọi đầu tốn 1200ms rồi timeout;
- hệ thống retry thêm một lần với timeout 1200ms nữa.
Dù lần retry thứ hai có thành công, user cũng đã chờ quá lâu. Tệ hơn, request đầu tiên và request retry có thể cùng giữ tài nguyên trên downstream nếu timeout xảy ra ở caller chứ không phải callee đã abort thật.
Nói cách khác: retry không có budget riêng, retry tiêu budget của toàn operation.
Các failure mode thường dẫn tới retry storm
1. Timeout đặt quá cao ở mọi tầng
Timeout cao làm caller chờ lâu, khiến inflight requests tích tụ. Khi timeout cuối cùng mới xảy ra, hệ thống đã ở trạng thái nghẹt hơn nhiều.
2. Retry đồng bộ ở nhiều layer cùng lúc
Ví dụ:
- mobile app retry;
- API gateway retry;
- service client library retry;
- queue worker retry;
- webhook dispatcher retry.
Nếu không có ownership rõ ràng, một lỗi tạm thời sẽ bị nhân lên nhiều cấp.
3. Không có jitter
Nếu 10.000 request cùng timeout ở mốc 500ms và cùng retry đúng sau 200ms, downstream sẽ bị “đập lại” theo từng nhịp sóng rất đều. Jitter giúp phá đồng bộ đợt retry này.
4. Retry cả lỗi không nên retry
Không phải lỗi nào cũng transient. Retry với:
- validation lỗi;
- auth lỗi;
- conflict nghiệp vụ;
- duplicate request không idempotent;
- deadlock do query pattern sai mà không có backoff;
thường chỉ làm tốn tải mà không cải thiện tỷ lệ thành công.
5. Không giới hạn concurrency hoặc retry budget
Nếu mỗi worker được retry không giới hạn trong lúc backlog tăng, hệ thống sẽ tạo thêm pressure ngay khi nên giảm pressure.
Phân bổ timeout budget như thế nào cho backend nhiều tầng?
Không có một con số đúng cho mọi hệ thống, nhưng có vài nguyên tắc rất thực chiến.
Nguyên tắc 1: deadline đi từ ngoài vào trong
Thay vì mỗi tầng tự chọn timeout độc lập, request nên mang theo một deadline hoặc remaining budget. Khi service A gọi B, nó truyền phần budget còn lại hoặc một phần đã cắt gọn.
Ví dụ với operation 1500ms:
- ingress/gateway reserve 100ms;
- service A business logic local: 150ms;
- call payment service: tối đa 500ms;
- call inventory service: tối đa 250ms;
- DB finalize + response: 200ms;
- phần còn lại làm safety margin.
Nếu payment service đã dùng hết 480ms, lần retry tiếp theo phải nhìn vào budget còn lại, không thể mù quáng lấy thêm 500ms mới.
Nguyên tắc 2: timeout phải ngắn hơn lúc user mất kiên nhẫn, nhưng dài hơn p99 khỏe mạnh
Timeout nên đủ để hấp thụ variance bình thường, nhưng không nên cao tới mức biến lỗi thành queueing disaster. Một cách thực dụng là nhìn latency distribution khỏe mạnh rồi đặt timeout quanh vùng p99/p99.5 theo loại dependency, có safety margin nhỏ, không phải gấp 5-10 lần median.
Nguyên tắc 3: mỗi lần retry phải rút ngắn cơ hội, không nhân đôi hy vọng
Nếu còn 300ms budget, không nên retry một call có timeout 500ms. Hoặc bỏ retry, hoặc dùng hedged/fallback khác phù hợp hơn.
Retry budget là gì và vì sao hữu ích?
Retry budget là một giới hạn để đảm bảo lượng retry không vượt quá một tỷ lệ cho phép so với traffic gốc. Ví dụ, hệ thống chỉ cho phép retry tối đa tương đương 20% request gốc trong một cửa sổ thời gian.
Ý nghĩa của retry budget:
- ép hệ thống thừa nhận rằng retry là tài nguyên hữu hạn;
- tránh trường hợp lỗi diện rộng biến thành bão request tự phát;
- buộc team ưu tiên retry cho đường critical hơn, thay vì retry mọi thứ như nhau.
Retry budget đặc biệt hữu ích cho:
- API clients gọi dependency nội bộ;
- background workers có backlog lớn;
- webhook delivery;
- third-party integrations có rate limit chặt.
Nên retry lỗi nào?
Retry hợp lý với các lỗi có tính chất transient và có xác suất thành công cao hơn ở lần sau, ví dụ:
- network reset ngắn;
- timeout ngẫu nhiên mức thấp khi dependency nhìn chung vẫn healthy;
- HTTP 502/503/504 trong thời gian ngắn;
- deadlock database nếu code xử lý transaction đúng và có backoff;
- broker publish thất bại tạm thời.
Không nên retry hoặc phải cực kỳ thận trọng với:
- HTTP 400/401/403/404 do input hoặc quyền;
- duplicate side effect khi endpoint không idempotent;
- business conflict cần user/action mới;
- saturation kéo dài mà không có dấu hiệu hồi phục;
- lỗi schema, serialization, contract mismatch.
Backoff và jitter: vì sao exponential backoff một mình chưa đủ?
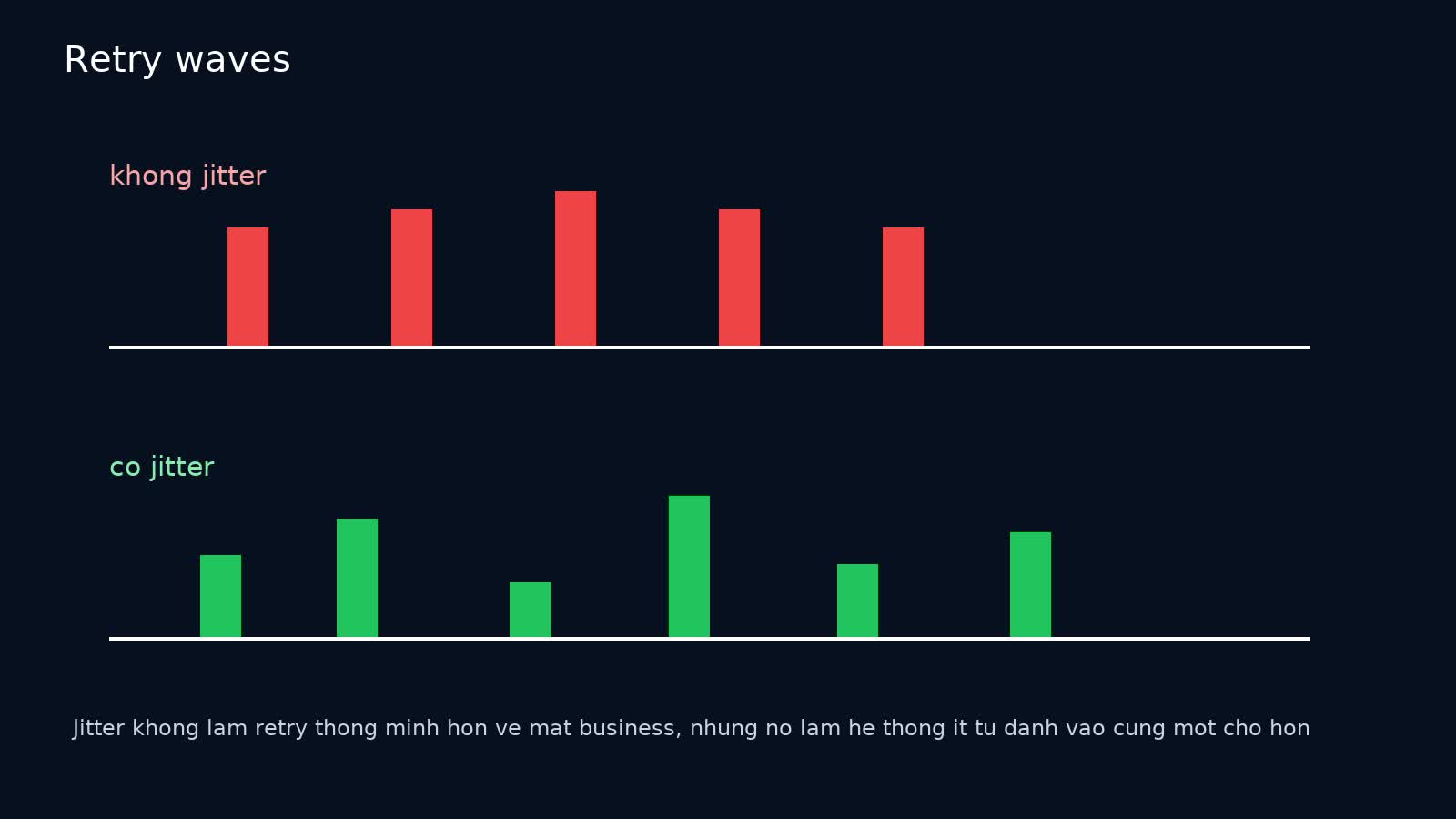
Exponential backoff giúp tăng thời gian chờ giữa các lần retry, nhưng nếu mọi caller cùng dùng chung công thức và cùng khởi phát một lúc, chúng vẫn có thể hội tụ thành từng đợt lớn.
Jitter thêm yếu tố ngẫu nhiên để phân tán các lần retry. Trong thực tế production, backoff without jitter là một anti-pattern đáng ngại.
Một policy thực tế thường gồm:
- số lần retry ít, ví dụ 1-2 lần cho synchronous path;
- exponential backoff bounded;
- full jitter hoặc decorrelated jitter;
- dừng retry khi deadline/budget không còn đủ;
- ưu tiên fallback nếu có.
Retry storm trong hệ thống fan-out nguy hiểm thế nào?
Một request user hiếm khi chỉ chạm một dependency. Nó có thể fan-out sang:
- profile service;
- pricing service;
- inventory service;
- recommendation service;
- fraud service;
- database + cache + event publish.
Chỉ cần một dependency trong số đó chậm, request tổng thể kéo dài. Nếu từng nhánh lại retry độc lập, fan-out sẽ biến thành retry amplification.
Ví dụ một request gọi 4 dependency, mỗi dependency retry thêm 1 lần khi timeout. Trong case xấu, số call outbound có thể tăng gần gấp đôi chỉ cho một request user. Khi traffic nền đủ lớn, hiệu ứng này rất tàn nhẫn.
Circuit breaker, adaptive concurrency, load shedding liên quan gì tới retry storm?
Retry storm hiếm khi được giải quyết chỉ bằng một nút “giảm retry”. Nó cần phối hợp nhiều guardrail.
Circuit breaker
Circuit breaker giúp fail fast khi dependency đang thực sự unhealthy. Khi breaker mở, retry thêm thường phải bị chặn hoặc chuyển sang fallback.
Adaptive concurrency limits
Nếu dependency chậm dần thay vì chết hẳn, adaptive concurrency limits có thể giảm số inflight requests để tránh congestion tăng theo dây chuyền.
Load shedding / backpressure
Khi system overload, phải có khả năng từ chối sớm một phần traffic ít quan trọng hơn là cho mọi request chờ đến chết.
Rate limiting
Rate limiting bảo vệ tổng lưu lượng và fairness, nhất là ở edge hoặc với tenant/client cụ thể, nhưng không thay thế được retry discipline trong nội bộ.
Idempotency là điều kiện để retry an toàn, không phải tính năng phụ
Một trong những lý do retry storm nguy hiểm là nhiều team vừa retry quá nhiều, vừa retry trên các operation có side effect không idempotent.
Ví dụ:
- tạo đơn hàng;
- tạo payment intent;
- gửi email xác nhận;
- publish webhook;
- trừ điểm thưởng.
Nếu retry xảy ra sau một partial success, hệ thống có thể vừa chịu thêm tải vừa tạo duplicate side effect. Vì vậy, trước khi mở retry cho một operation write, cần trả lời rõ:
- operation có idempotency key hoặc natural dedupe chưa?
- caller có thể phân biệt timeout-before-execute và timeout-after-commit không?
- downstream có outbox/processed-event table nếu flow là async không?
Observability: làm sao biết mình đang có retry storm?
Một retry storm đẹp đẽ trên dashboard tổng quát có thể trông giống “traffic tăng bất thường”. Cần instrument đúng.
Metric nên có
- total requests gốc vs total retries;
- retry rate theo dependency, route, status code;
- timeout rate theo hop;
- inflight requests;
- queue depth / queue age;
- connection pool wait time;
- circuit breaker open rate;
- success after retry vs total retries.
Log/trace nên có
- request deadline hoặc remaining timeout budget;
- attempt number;
- retry reason;
- dependency target;
- idempotency key / operation key;
- trace linkage giữa original request và retry attempts.
Một câu hỏi rất thực tế trong incident là: retry có đang cứu được request nào không, hay chỉ tạo thêm tải? Nếu metric không trả lời được câu này, team đang bay mù.
Incident pattern: downstream chậm nhẹ nhưng hệ thống sập vì retry
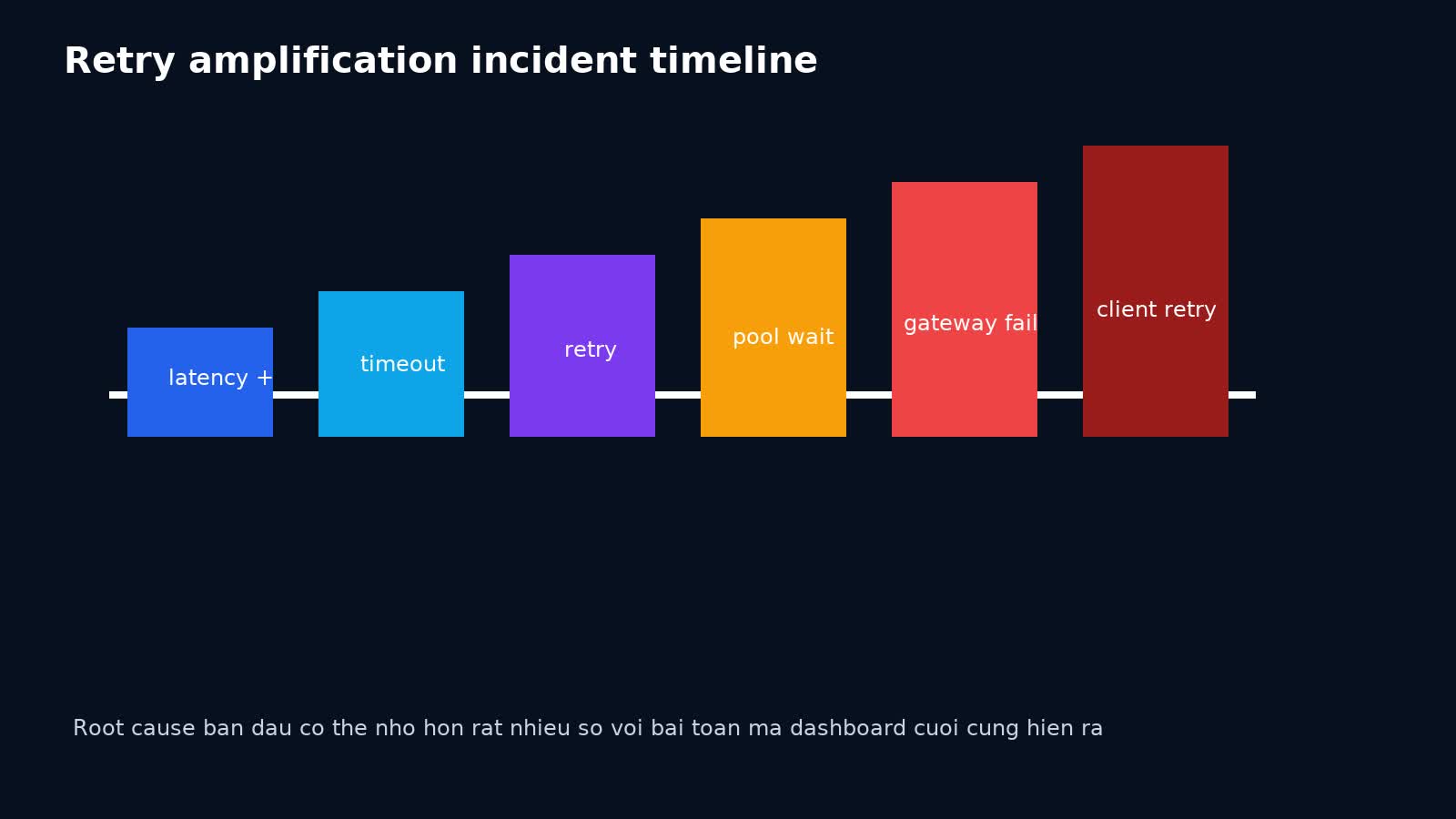
Đây là pattern rất phổ biến:
- database hoặc payment provider chậm thêm 300-500ms;
- service upstream bắt đầu timeout ở ngưỡng quá sát hoặc quá cứng;
- client library retry ngay lập tức;
- inflight tăng;
- pool wait time tăng;
- gateway timeout;
- client ngoài retry tiếp;
- CPU, thread, queue đều xấu hơn;
- breaker mở muộn hoặc mở không đủ mạnh;
- incident giờ trông như “mọi thứ cùng hỏng”.
Root cause ban đầu có thể rất nhỏ so với blast radius cuối cùng. Đây là lý do production review nên hỏi không chỉ “dependency nào chậm?”, mà còn “policy retry nào đã khuếch đại sự cố?”.
Checklist thiết kế retry an toàn cho backend production

Với synchronous request path
- [ ] Có deadline tổng thể rõ ràng cho operation.
- [ ] Timeout của từng dependency được cắt theo remaining budget.
- [ ] Retry tối đa 1-2 lần, không hơn, cho path user-facing.
- [ ] Có jitter, không retry đồng pha.
- [ ] Chỉ retry lỗi transient đã định nghĩa rõ.
- [ ] Có circuit breaker hoặc fail-fast guardrail cho dependency unhealthy.
- [ ] Có idempotency nếu operation có side effect.
Với async worker / queue consumer
- [ ] Retry policy tách khỏi user-facing path.
- [ ] Có retry budget hoặc concurrency cap.
- [ ] Có DLQ / quarantine path sau max attempts.
- [ ] Không để backlog cũ tự sinh bão retry khi downstream degraded.
- [ ] Có alert theo oldest message age, không chỉ message count.
Với third-party integration
- [ ] Tôn trọng rate limit / Retry-After.
- [ ] Dùng backoff + jitter bounded.
- [ ] Có fallback hoặc degraded mode khi vendor lỗi kéo dài.
- [ ] Không để nhiều service cùng retry một vendor mà không chia sẻ policy.
Anti-pattern phổ biến
“Retry cho chắc” ở mọi tầng
Đây là con đường ngắn nhất tới retry storm.
Timeout 30 giây cho hầu hết outbound call
Timeout dài nghe có vẻ an toàn nhưng thực ra dễ tạo queueing collapse.
Coi retry thành cách che giấu độ trễ nền
Nếu dependency thường xuyên chỉ thành công sau 1 lần retry, vấn đề là dependency hoặc timeout policy, không phải “retry đang làm tốt”.
Không đo success-after-retry
Nếu 95% retry vẫn fail, policy đó chủ yếu tạo thêm tải. Cắt bớt thường tốt hơn.
Không phân loại operation theo mức quan trọng
Không phải request nào cũng xứng đáng tiêu cùng một retry budget. Health check, analytics write, email non-critical và payment authorization không nên được đối xử như nhau.
Kết luận
Retry là công cụ mạnh, nhưng trong backend production nó phải bị đối xử như một khoản nợ có lãi suất cao: dùng đúng lúc thì cứu hệ thống, dùng bừa thì tự khuếch đại lỗi.
Cách tiếp cận vững hơn là nghĩ theo timeout budget + retry budget + idempotency + guardrails. Mỗi outbound call phải biết mình còn bao nhiêu thời gian, có đáng retry không, retry bao nhiêu là đủ, và khi dependency yếu thì hệ thống sẽ giảm tải bằng cách nào.
Nếu team của bạn thường chỉ thêm retry sau mỗi incident mà ít xem lại deadline propagation, breaker, concurrency limit hay backpressure, rất có thể hệ thống đang tích sẵn điều kiện cho một retry storm lớn hơn ở lần tới.
Đọc tiếp trong cluster backend reliability
- Circuit Breaker trong Backend Production
- Backpressure và Load Shedding trong Backend
- Adaptive Concurrency Limits trong Backend Production
- Webhook Idempotency trong Payment Systems
- Distributed Locks trong Backend Production
- Queue-Based Load Leveling trong Backend Production
- Flaky Test CI Quarantine và Retry Budget