Hedged Requests trong Backend Production: cắt tail latency mà không tự đốt hạ tầng
Nhiều hệ thống backend không chậm ở median. Chúng chậm ở đuôi phân phối latency. P50 vẫn đẹp, dashboard nhìn tưởng ổn, nhưng P95/P99 thỉnh thoảng vọt lên đủ để làm user thấy lag, làm timeout dây chuyền, và bào mòn error budget theo cách rất khó chịu. Một trong những kỹ thuật mạnh nhưng dễ bị hiểu sai để xử lý chuyện này là hedged requests.
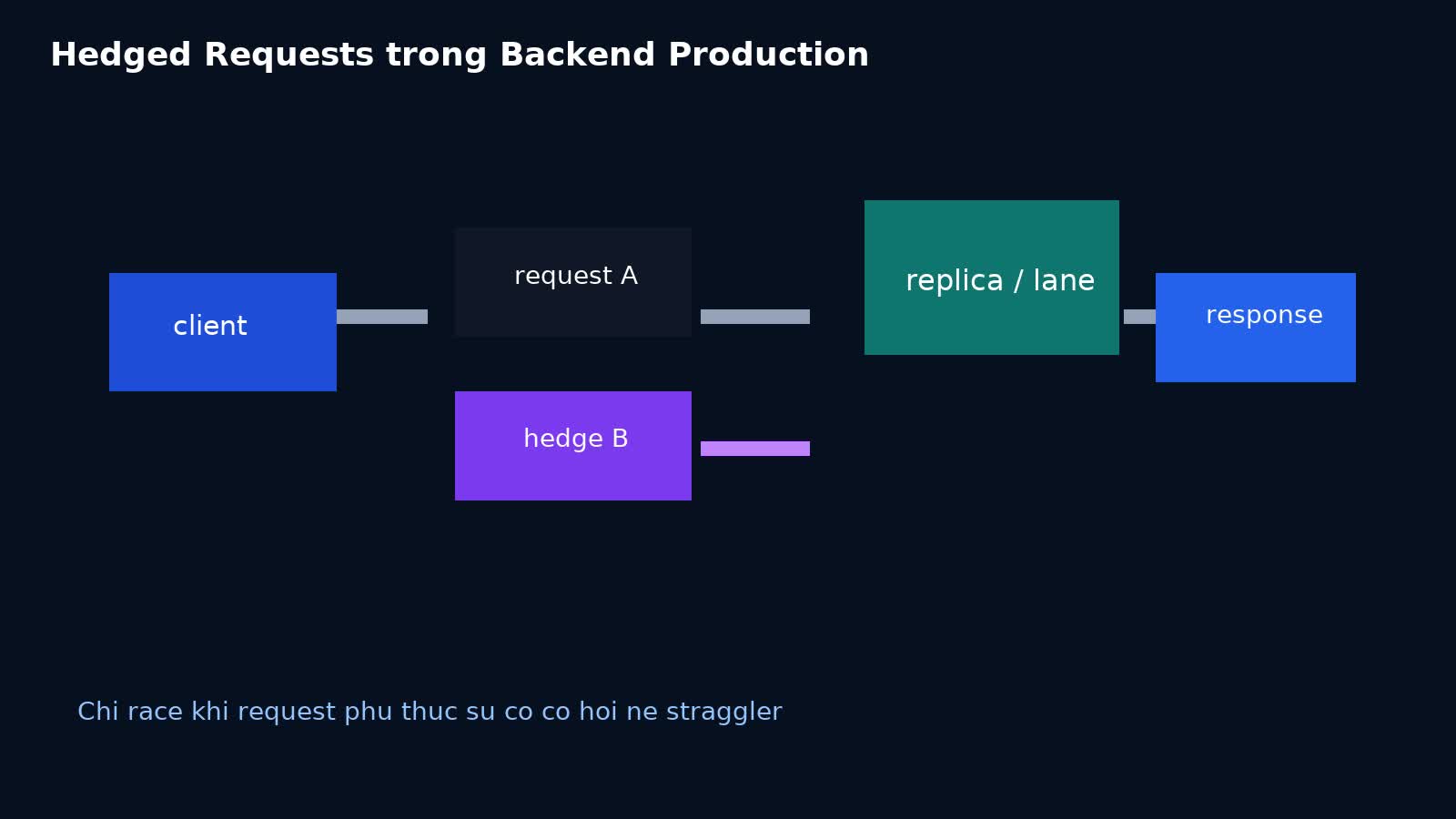
Ý tưởng nghe khá đơn giản: nếu một request gốc đang chậm bất thường, sau một khoảng delay ngắn ta gửi thêm một request song song tương đương tới replica hoặc lane khác; ai trả lời trước thì lấy kết quả, request còn lại bị hủy. Cách này có thể cắt đáng kể tail latency trong các hệ thống đọc phân tán, RPC tới nhiều replica, hoặc dịch vụ mà variance chủ yếu đến từ straggler node. Nhưng nếu áp dụng sai, hedging sẽ nhanh chóng biến thành cách lịch sự để tự nhân traffic lên rồi gọi đó là tối ưu hiệu năng.
Bài này đi thẳng vào mặt production của hedged requests: bài toán nó giải quyết, khi nào đáng dùng, hedge delay nên đặt thế nào, khác gì retry, điều kiện idempotency ra sao, kết hợp với timeout/circuit breaker/concurrency limit như thế nào, và những anti-pattern khiến P99 chưa giảm mà hạ tầng đã mệt trước.
Hedged requests thực chất giải bài toán gì?
Hedged requests không dành cho mọi loại chậm. Nó nhắm vào một class vấn đề khá cụ thể: straggler latency.
Đó là những tình huống như:
- một replica đang GC hoặc bị noisy neighbor nên trả chậm hơn phần còn lại;
- một connection path bị queue cục bộ hoặc network jitter ngắn;
- một shard/worker vẫn sống nhưng phản ứng bất thường trong một khoảng rất ngắn;
- một distributed read cần đợi một lane cụ thể, trong khi lane khác có thể trả kết quả tương đương nhanh hơn.
Nếu nguyên nhân gốc là toàn hệ thống đang quá tải, database lock diện rộng, hoặc downstream nào cũng chậm như nhau, hedging không cứu được nhiều. Lúc đó anh chỉ đang gửi thêm nhiều request vào một chỗ vốn đã mệt.
Điểm mấu chốt là: hedging tối ưu variance, không chữa saturation.
Vì sao P99 quan trọng hơn cảm giác “trung bình vẫn ổn”?
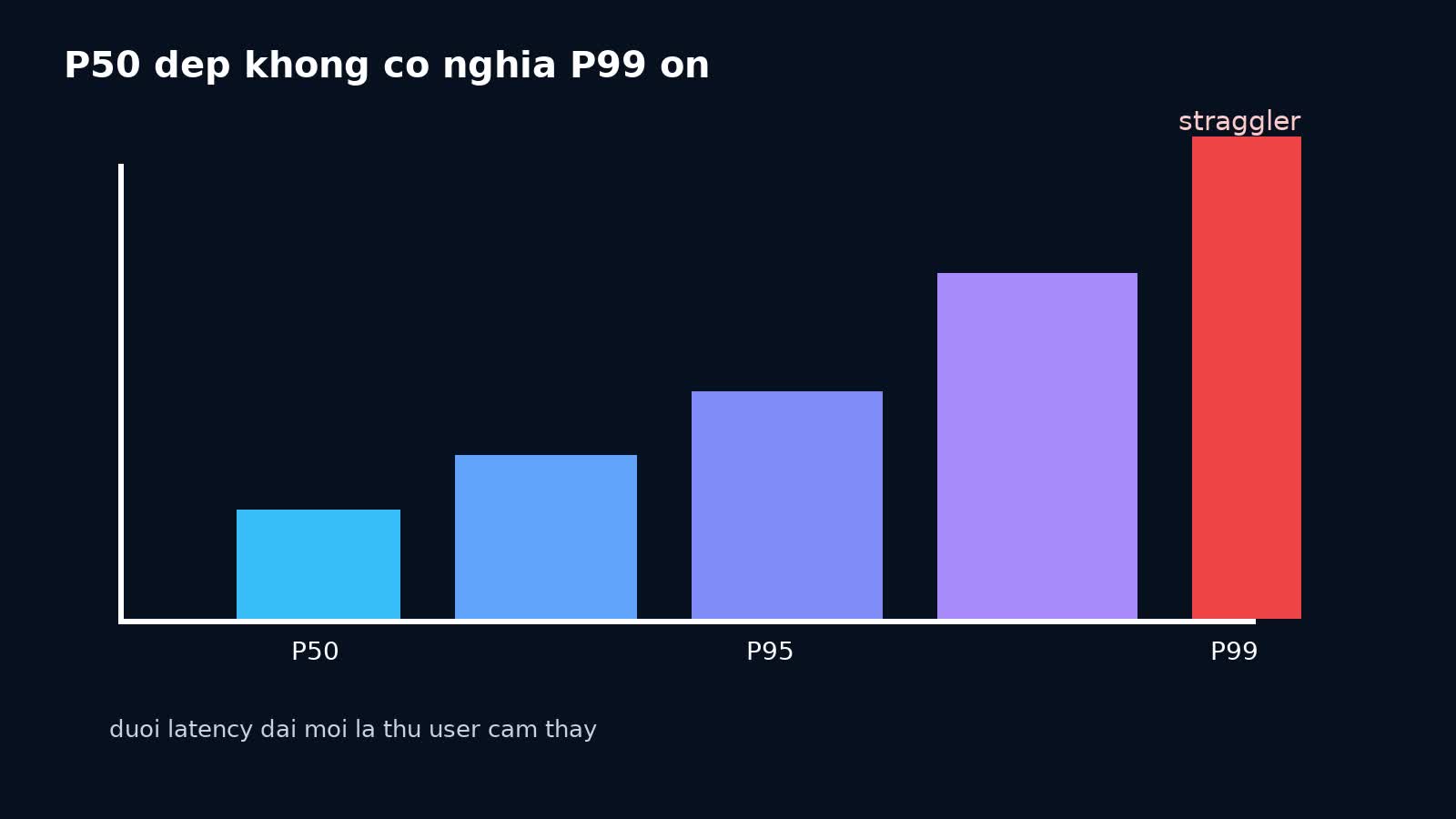
Trong production, user không cảm nhận P50. Họ cảm nhận những lần xấu nhất đủ thường xuyên để thành khó chịu. Với một API có P50 = 80ms nhưng P99 = 2.5s, trải nghiệm thực tế vẫn có thể bị xem là chậm, nhất là khi API đó nằm trong critical path của:
- render trang cần nhiều downstream fan-out;
- checkout, search, recommendation hoặc dashboard doanh nghiệp;
- orchestrator gọi nhiều service con;
- worker chain mà một node chậm kéo cả pipeline chậm theo.
Tail latency còn nguy hiểm ở chỗ nó gây timeout stacking. Một request upstream chờ quá lâu sẽ:
- giữ connection lâu hơn;
- tăng số request in-flight;
- khiến queue age tăng;
- tạo áp lực retry nếu client phía trên thiếu kỷ luật.
Hedged requests, khi dùng đúng, giúp giảm xác suất đụng phải straggler kéo dài ở critical path.
Hedged requests khác gì retry?
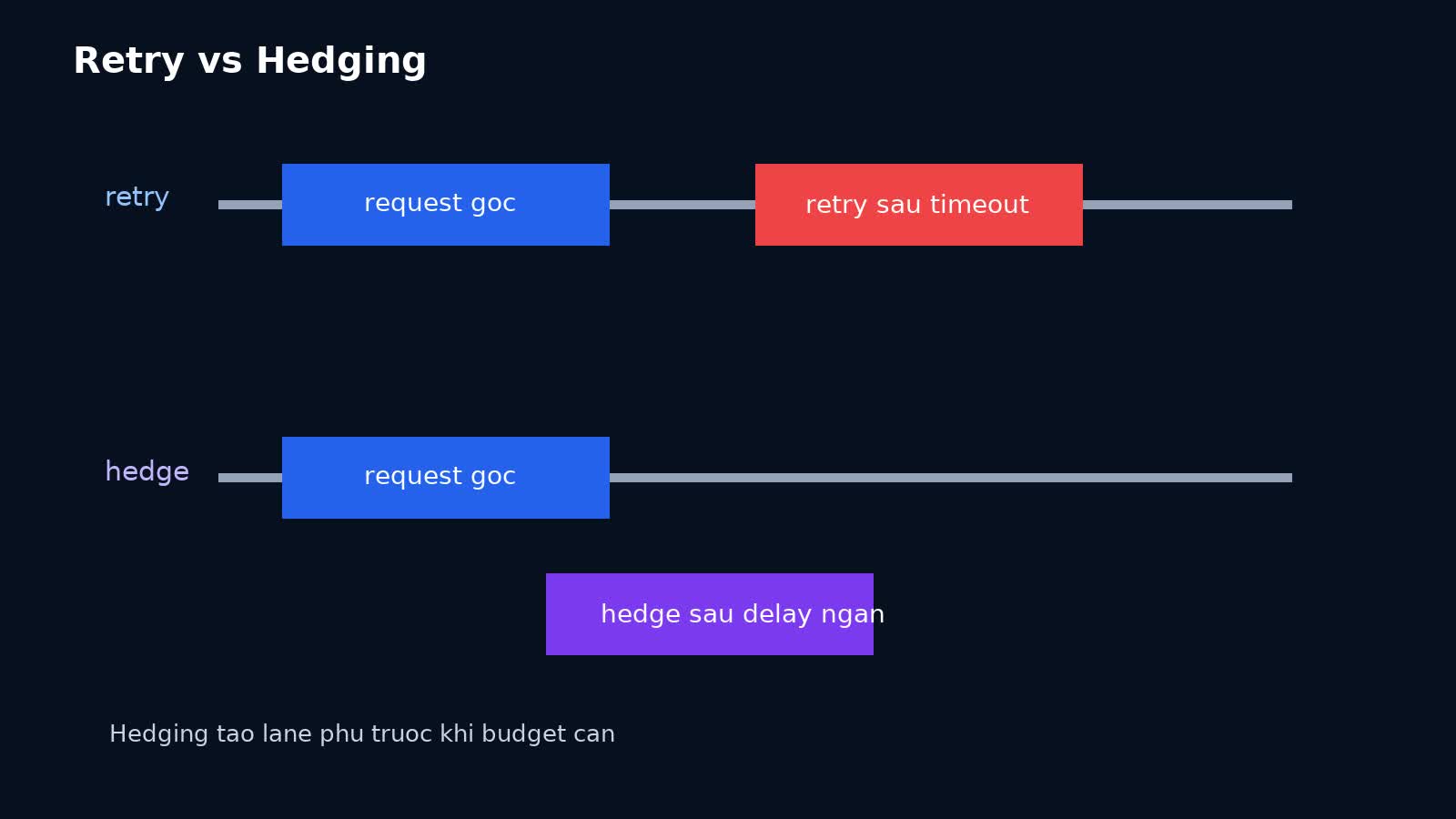
Đây là chỗ rất nhiều team nhầm.
Retry
Retry xảy ra sau khi request thất bại hoặc timeout. Nó phản ứng hậu sự kiện. Nếu timeout là 1 giây và retry thêm một lần, user có thể chờ hơn 2 giây trước khi nhận kết quả.
Hedging
Hedging xảy ra trước khi timeout chính thức, nhưng chỉ khi request gốc có dấu hiệu đang trở thành outlier. Thay vì chờ nó chết hẳn, ta tạo một request thứ hai sau một hedge delay, thường là một phần nhỏ của timeout budget.
Nói ngắn gọn:
- retry = “thử lại sau khi request đầu đã fail hoặc quá muộn”;
- hedging = “thử lane khác trước khi xác suất chậm kéo dài trở thành sự thật”.
Hedging vì vậy có thể cải thiện latency tốt hơn retry trong một số đọc phân tán. Nhưng cái giá là amplification load có chủ đích. Anh đang chấp nhận trả thêm một ít chi phí hệ thống để mua xác suất latency ổn định hơn.
Điều kiện tiên quyết: request phải an toàn để race
Không phải request nào cũng được hedge.
Hedging phù hợp nhất cho:
- read-only query có semantics giống nhau giữa các replica;
- idempotent RPC mà duplicate execution không tạo side effect nguy hiểm;
- truy vấn có thể cancel phần thua một cách rõ ràng;
- workload mà kết quả từ lane A hay lane B là tương đương ở mức business.
Hedging rất rủi ro cho:
- thao tác tạo thanh toán, trừ tồn kho, gửi email, phát webhook;
- mutation không có idempotency key mạnh;
- flow mà race hai request có thể nhân side effect;
- downstream không hỗ trợ cancellation thực sự, khiến request thua vẫn chạy hết việc ở server.
Một nguyên tắc thực tế: nếu anh không dám chạy request đó hai lần gần như đồng thời, đừng hedge.
Hedge delay nên đặt thế nào?
Đây là tham số quan trọng nhất. Nếu hedge quá sớm, anh nhân traffic gần như mọi request. Nếu quá muộn, request gốc đã ăn gần hết timeout budget và hiệu quả giảm tail latency giảm mạnh.
Cách nghĩ đúng về hedge delay
Hedge delay nên bám vào phân phối latency thực tế của endpoint, không dùng cảm tính. Một số team chọn:
- gần P95 của endpoint;
- một percentile thấp hơn nếu critical path rất nhạy với P99;
- một delay động theo route, theo dependency, hoặc theo class traffic.
Ví dụ:
- timeout end-to-end của call là 800ms;
- P50 của dependency là 70ms;
- P95 là 220ms;
- P99 là 900ms.
Một hedge delay khoảng 180–250ms có thể hợp lý hơn nhiều so với việc cố định 50ms hoặc 500ms cho mọi request.
Đừng quên timeout budget toàn chuỗi
Nếu endpoint của anh fan-out tới 4 downstream, mỗi downstream tự hedge và mỗi cái lại có timeout riêng quá rộng, tổng chi phí tài nguyên có thể nổ nhanh. Hedge delay phải được thiết kế trong latency budget toàn request graph, không phải tối ưu cục bộ cho một service rồi mặc kệ upstream.
Load amplification: cái giá phải trả để mua latency đẹp hơn
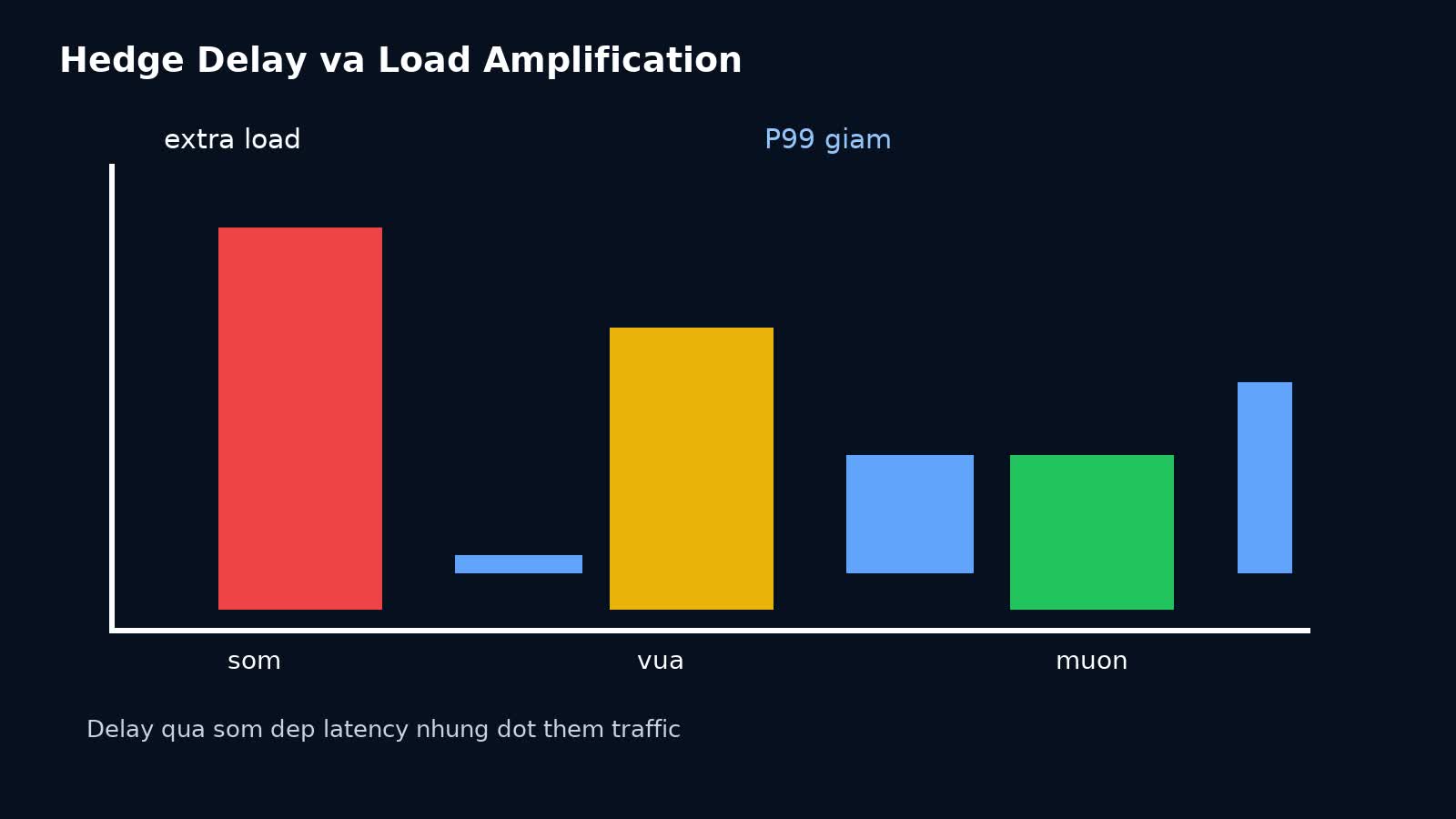
Hedged requests luôn tạo thêm load, dù có kiểm soát. Câu hỏi không phải là “có tăng load không?”, mà là “mức tăng đó có đáng để đổi lấy tail latency thấp hơn không?”.
Một cách nhìn hữu ích:
- nếu chỉ 2–5% request trở thành hedge, amplification có thể chấp nhận được;
- nếu 30–40% request đều hedge, anh không còn tối ưu straggler nữa, anh đang chạy một mô hình traffic mới.
Metrics quan trọng cần theo dõi:
- hedge rate: tỷ lệ request phát sinh hedge;
- hedge win rate: tỷ lệ request phụ thắng request gốc;
- hedge wasted work: số request phụ bị hủy sau khi request gốc đã sắp xong;
- extra CPU/network/QPS do hedging;
- tail latency trước và sau khi hedge.
Nếu hedge rate tăng dần theo thời gian, đó thường là tín hiệu hệ thống đang xấu đi hoặc tham số hedge delay quá hung hãn.
Cancellation không tốt thì hedging chỉ là nhân đôi công việc
Một hedged request đẹp trên slide là:
- request gốc đi tới replica A;
- sau hedge delay, request phụ đi tới replica B;
- replica B trả trước;
- caller cancel request A;
- upstream giải phóng tài nguyên sớm.
Nhưng ngoài đời, cancellation thường không sạch đến vậy.
Các vấn đề phổ biến:
- client hủy nhưng server vẫn xử lý gần xong;
- DB query không bị kill ngay;
- thread pool ở downstream vẫn giữ tài nguyên cho request thua;
- proxy hoặc library không propagate cancellation semantics tốt.
Khi đó, anh vẫn nhận được latency đẹp hơn ở caller nhưng hạ tầng tổng thể phải làm gần gấp đôi việc. Nếu không đo phần wasted work, dashboard latency có thể đẹp giả.
Replica diversity quan trọng hơn việc chỉ “gửi thêm một request nữa”
Hedging có tác dụng mạnh nhất khi request phụ thật sự có cơ hội tránh lane xấu.
Ví dụ tốt:
- request phụ đi tới replica khác trong cùng cluster;
- request phụ đi qua connection pool khác hoặc zone khác;
- client-side load balancer ưu tiên endpoint khác với request gốc;
- storage read có nhiều replica và caller biết chọn replica độc lập.
Ví dụ kém hiệu quả:
- cả hai request đều chui qua cùng một queue nội bộ;
- cùng đụng một shard nóng;
- cùng đi vào một DB primary đang lock;
- cùng bị rate limit ở một upstream gateway chung.
Nói cách khác, hedging chỉ có giá trị khi có diversity trong failure surface.
Kết hợp hedging với timeout, circuit breaker và concurrency limit
Hedging không nên đứng một mình.
Timeout
Mỗi request race vẫn phải có deadline rõ. Nếu hedge mà timeout lỏng, anh sẽ tạo thêm request sống dai và làm mọi thứ tệ hơn.
Circuit breaker
Nếu dependency đang unhealthy diện rộng, breaker phải có quyền chặn việc hedge thêm. Không thể để request gốc đã khó sống lại còn sinh request phụ vào cùng dependency đang mở mạch.
Concurrency limit / bulkhead
Cần quota riêng cho hedged requests hoặc ít nhất giới hạn tổng in-flight per dependency. Nếu không, trong lúc tail latency xấu lên, số request hedge tăng và chính nó đẩy hệ thống sang overload thật.
Một pattern thực dụng là:
- chỉ cho hedge trên một số endpoint read critical;
- đặt cap số hedge đang hoạt động;
- tắt hedging tự động khi dependency saturation vượt ngưỡng.
Khi nào hedged requests đáng dùng?
Đây là các tình huống khá hợp lý:
1. Distributed read có nhiều replica độc lập
Ví dụ search index replica, key-value store replica, read-only cache cluster, hoặc RPC tới nhiều backend đồng dạng.
2. Tail latency do straggler ngắn hạn lớn hơn chi phí thêm một ít request phụ
Nếu business cực nhạy với P99, như search suggestions, timeline feed, pricing read hoặc dashboard điều hành, hedging có thể đáng tiền.
3. Workload chủ yếu là read, có thể cancel phần thua và duplicate không gây side effect
Đây gần như là điều kiện đẹp nhất.
Khi nào không nên dùng?
1. Hệ thống đang bottleneck vì saturation thật
Nếu CPU, DB, queue, network đều đang căng, hedging chỉ làm điều xấu đến nhanh hơn.
2. Mutation không idempotent
Không có gì đáng sợ bằng việc tối ưu P99 bằng cách thỉnh thoảng tạo side effect gấp đôi.
3. Không có observability đủ sâu
Nếu anh không đo được hedge rate, hedge win rate, wasted work và saturation downstream, anh đang lái xe ban đêm mà tắt đèn.
4. Request graph đã quá phức tạp và nhiều tầng tự retry
Lúc đó nên dọn deadline budget, retry budget, backpressure và breaker trước khi nghĩ tới hedging.
Một mô hình rollout an toàn cho hedged requests
Đừng bật toàn hệ thống một lần.
- Chọn 1 endpoint read có traffic đủ lớn và có nhiều replica.
- Đo baseline P50/P95/P99, QPS, CPU, network, cancellation success, saturation downstream.
- Bật hedging cho 1–5% traffic với hedge delay bảo thủ.
- So sánh:
- P99 giảm bao nhiêu;
- hedge rate bao nhiêu;
- extra load bao nhiêu;
- downstream có nóng hơn không.
- Tăng dần rollout nếu trade-off còn đẹp.
- Chuẩn bị kill switch để tắt ngay khi hedge amplification vượt kiểm soát.
Điều tôi thích ở approach này là nó buộc team xem hedging như một đòn trade-off có đo lường, không phải mẹo thần kỳ.
Observability checklist cho hedged requests

Tối thiểu nên có các metric sau theo từng dependency/route:
- request count gốc;
- hedge request count;
- hedge rate;
- hedge win rate;
- median và tail latency trước/sau hedge;
- cancellation sent rate;
- cancellation acknowledged rate nếu đo được;
- wasted work estimate;
- downstream QPS amplification;
- timeout rate và breaker-open rate sau khi bật hedge.
Trace cũng nên cho thấy:
- request nào là original, request nào là hedge;
- hedge delay đã áp dụng;
- replica/endpoint đích của từng lane;
- lane nào thắng;
- lane nào bị cancel;
- total deadline còn lại khi hedge phát sinh.
Nếu không có trace class này, việc debug “tại sao p99 đẹp hơn nhưng CPU lại tăng” sẽ rất đau đầu.
Anti-pattern phổ biến
1. Hedge mọi request read
Hedging là dao mổ, không phải búa. Chỉ nên áp dụng vào route đủ quan trọng và đủ phù hợp.
2. Dùng hedge delay cố định cho mọi dependency
Mỗi dependency có profile latency khác nhau. Dùng một delay chung gần như chắc chắn làm quá tay ở chỗ này và quá chậm ở chỗ khác.
3. Bật hedging khi retry policy đã rối
Nếu một request có thể bị SDK retry, service retry, queue retry, rồi còn hedge nữa, anh đã tạo một mê cung amplification.
4. Không tách quota cho hedged traffic
Khi tail latency xấu đi, request hedge tăng, rồi chính hedged traffic cướp tài nguyên của traffic gốc.
5. Dùng hedging để che issue nền tảng
Nếu một replica thường xuyên chậm vì GC pause, disk latency hoặc query plan xấu, root cause vẫn cần sửa. Hedging chỉ nên là control để giảm ảnh hưởng, không phải giấy dán lên vết nứt.
Internal link opportunities trong cluster softwareengineer.vn
- Khi nói về retry amplification và fail-fast, nối sang bài
/circuit-breaker-backend-production/. - Khi nói về saturation thay vì variance, nối sang
/backend-backpressure-load-shedding/. - Khi nói về latency budget và reliability target, nối sang
/sli-slo-error-budget-production/. - Khi nói về stale read hay replica behavior, nối sang
/read-after-write-consistency-replica-lag-production/. - Khi nói về distributed coordination hoặc multiple replicas không đồng nghĩa semantics như nhau, nối sang
/distributed-locks-backend-production/.
Kết luận
Hedged requests là một kỹ thuật rất đáng giá khi bài toán thật sự là tail latency do straggler, request có thể race an toàn, downstream có diversity đủ tốt, và team chịu đo đầy đủ cái giá của amplification. Nó không phải bản nâng cấp tự nhiên của retry, cũng không phải thuốc chữa cho saturation.
Nếu phải chốt trong một câu, tôi sẽ chốt thế này: hedge để mua xác suất thoát khỏi lane xấu, không phải để cầu may trước một hệ thống đang quá tải diện rộng.
Làm đúng, anh có thể kéo P99 xuống đáng kể mà không phá hỏng kiến trúc. Làm sai, anh sẽ chỉ biến cùng một workload thành hai request thay vì một, rồi ngạc nhiên vì sao latency chưa kịp đẹp bao lâu thì cụm máy đã nóng hơn hẳn.