Connection Leak và Pool Exhaustion trong Backend Production: vì sao database không chết ngay mà request chết dần
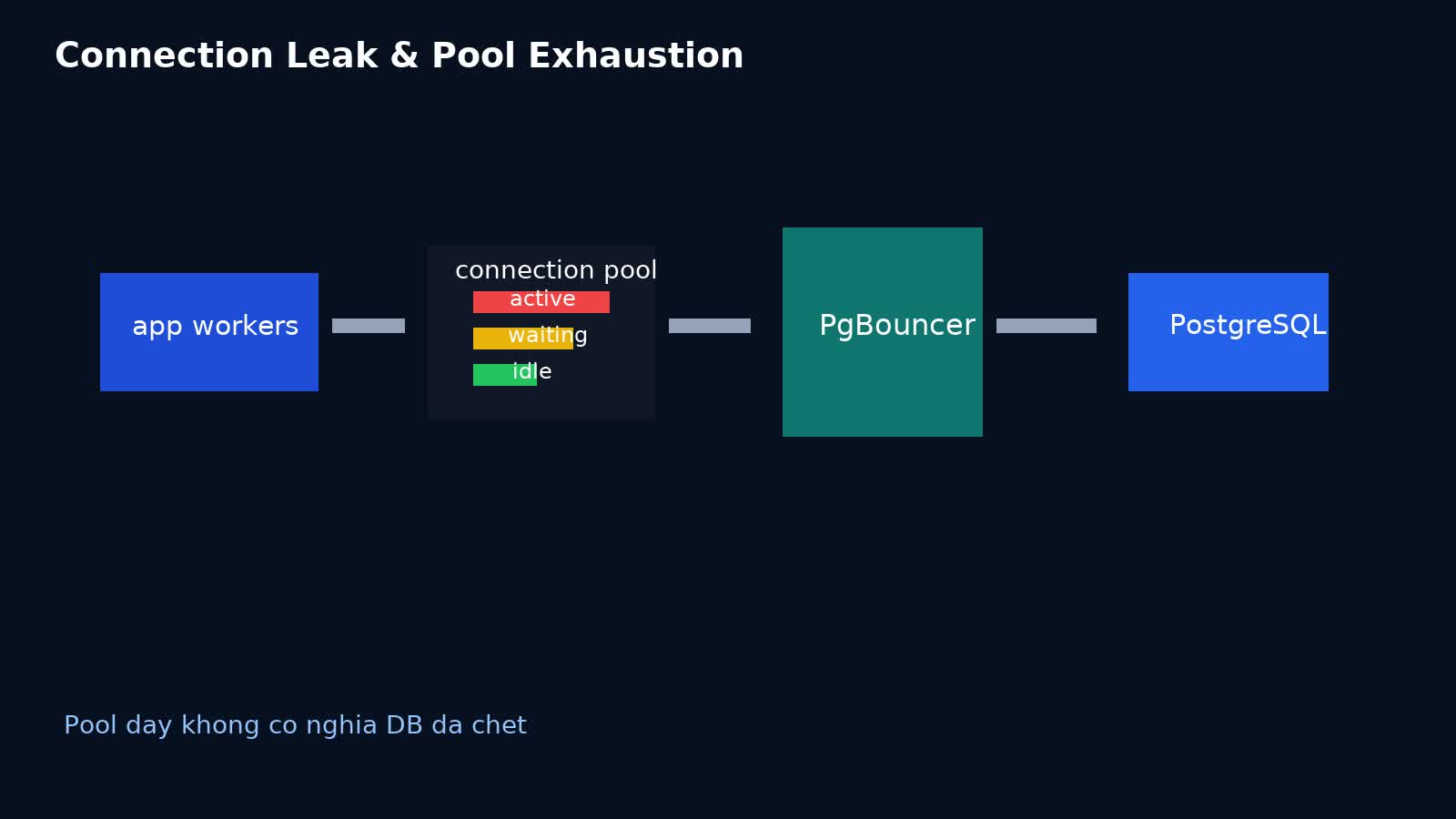
Nhiều incident database không bắt đầu bằng một tiếng nổ lớn. Không có CPU 100% ngay lập tức. Không có disk full rõ ràng. Thứ team thấy trước thường là request treo lâu hơn bình thường, timeout tăng dần, thread worker bắt đầu xếp hàng, rồi cuối cùng cả API trông như đang chết chậm. Một trong những nguyên nhân khó chịu nhất của kiểu suy sụp này là connection leak hoặc pool exhaustion.
Đây là failure mode rất dễ bị chẩn đoán nhầm. Người ta thường đổ lỗi cho database chậm, query plan xấu, network chập chờn, hoặc ORM “tự dưng dở chứng”. Nhưng ở khá nhiều ca production, database vẫn còn sống, query đơn lẻ vẫn chạy được, chỉ có điều application đã tiêu hết khả năng mượn connection để làm việc tử tế.
Bài này đi thẳng vào góc nhìn production engineering: connection leak khác gì pool exhaustion, vì sao pool đầy nhưng database chưa chắc đang chết, cách đọc symptom theo request path, transaction scope, ORM/session lifecycle, PgBouncer, timeout, graceful shutdown, và checklist để lần sau không phải mò lại từ đầu.
Connection leak và pool exhaustion khác nhau ở đâu?
Hai khái niệm này hay bị dùng lẫn, nhưng không hoàn toàn giống nhau.
Connection leak
Connection leak xảy ra khi application mượn connection rồi không trả lại pool đúng lúc, hoặc giữ nó lâu hơn rất nhiều so với ý định ban đầu. Leak không nhất thiết là “mất vĩnh viễn”. Chỉ cần connection bị giữ trong thời gian quá dài so với tốc độ traffic là pool cũng đủ nghẹt.
Các dạng leak thường gặp:
- code path exception không đi qua nhánh
finally/deferđể release; - transaction mở rồi return sớm;
- stream/cursor mở nhưng không đóng;
- background job giữ session xuyên nhiều bước I/O;
- ORM session scope gắn sai vào lifecycle request;
- connection bị giữ trong lúc gọi external API hoặc chờ lock.
Pool exhaustion
Pool exhaustion là trạng thái không còn connection rảnh để cấp cho request mới. Pool đầy không bắt buộc do leak. Nó cũng có thể đến từ:
- concurrency tăng đột biến;
- query quá chậm;
- transaction giữ connection lâu;
- pool size nhỏ hơn thực tế cần;
- worker count/app instance tăng nhưng database max connections không theo kịp;
- shutdown/deploy tạo nhiều connection treo ngắn hạn.
Nói ngắn gọn: leak là một nguyên nhân, còn pool exhaustion là triệu chứng hệ thống thấy được.
Vì sao database chưa chết mà API đã chết dần?
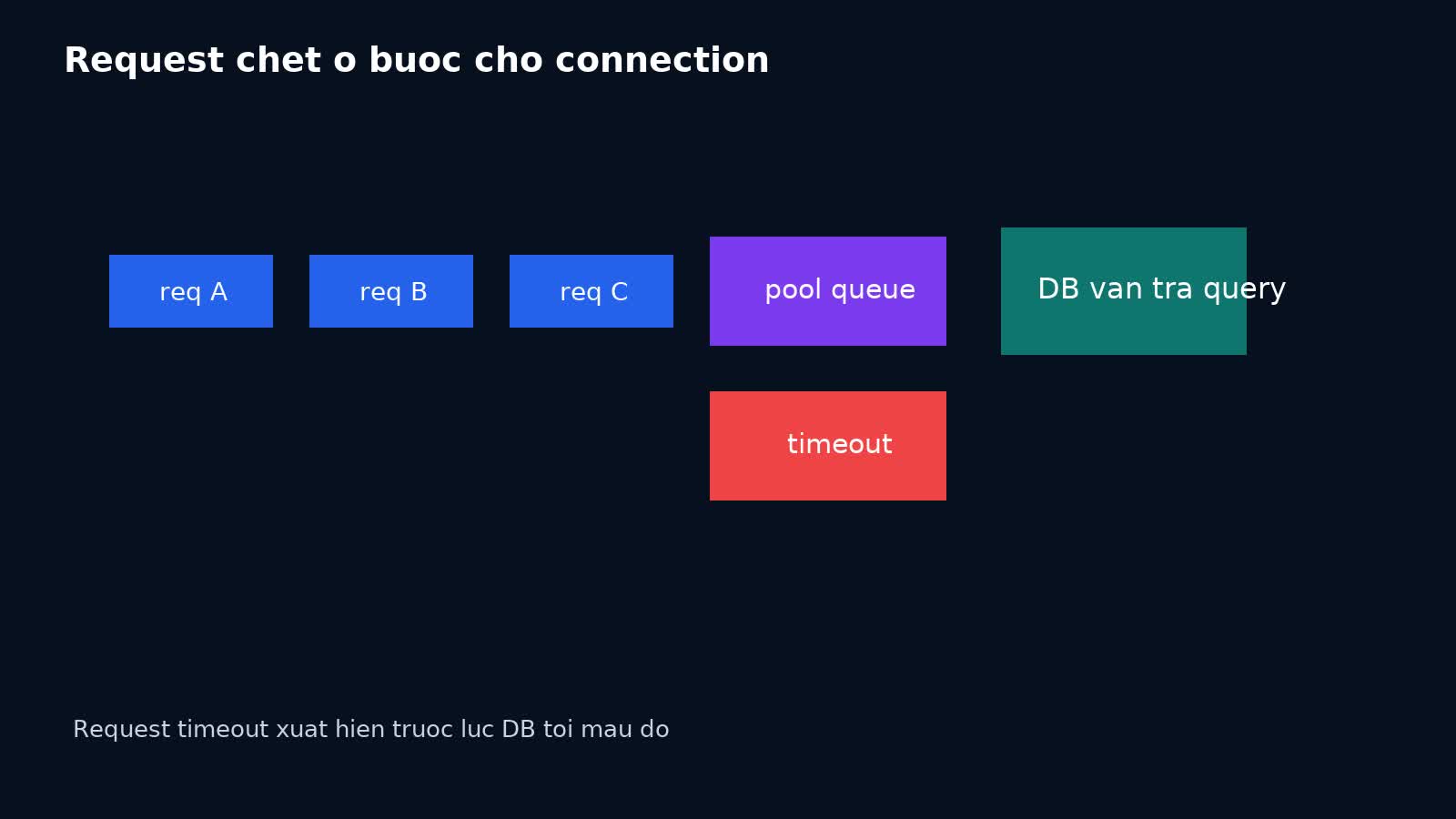
Đây là chỗ rất nhiều team bị lừa cảm giác.
Nếu anh SSH vào DB và chạy một query đơn giản, nó vẫn có thể trả về nhanh. CPU database không nhất thiết đỏ. Nhưng application lại timeout hàng loạt vì worker không lấy nổi connection từ pool. Request không chết ở bước thực thi SQL; nó chết ở bước xếp hàng chờ quyền được chạm vào database.
Dạng symptom điển hình:
- latency tăng trước ở nhóm endpoint cần DB;
- request queue trong app server tăng;
- timeout
acquire connectionhoặcpool timeoutxuất hiện; - HTTP 5xx tăng muộn hơn latency;
- database dashboard không xấu tương xứng với mức user đang than;
- restart app “có vẻ khỏi” trong vài phút rồi tái phát.
Đây là lý do pool exhaustion nguy hiểm: nó làm team nhìn sai tầng. Nếu chỉ nhìn query latency ở DB, anh có thể kết luận “database vẫn ổn”. Thực tế application đang nghẹt ở tầng connection management.
Dấu hiệu nào khiến tôi nghi leak trước khi nghi query chậm?
Không có một metric thần kỳ, nhưng vài pattern rất đáng ngờ:
1. Active connection tăng dần rồi không quay về baseline
Traffic bình thường giảm nhưng số connection đang bận vẫn neo cao bất thường. Điều này thường gợi ý có connection bị giữ lâu hơn mức request lifecycle hợp lý.
2. Timeout xuất hiện ở bước acquire trước cả khi query chạy
Nhiều framework/log sẽ ghi rõ kiểu lỗi như:
timeout acquiring a connection from the poolQueuePool limit reachedcould not obtain JDBC connectioncontext deadline exceeded while waiting for connection
Nếu request fail trước khi câu SQL chính chạy, nghi ngờ nên dồn vào pool trước.
3. Restart app giảm lỗi ngay nhưng không sửa gốc rễ
Restart giải phóng session/connection mắc kẹt, nên symptom biến mất tạm. Nếu sau đó lỗi quay lại theo cùng pattern, đây là dấu hiệu rất mạnh của lifecycle bug hoặc retention quá lâu ở app layer.
4. Chỉ một vài endpoint hoặc job làm nổ pool
Nếu toàn site chậm đều, có thể là DB hoặc network diện rộng. Nếu chỉ một nhóm endpoint, một worker queue, hoặc một cron/backfill khiến pool cạn nhanh, root cause thường nằm ở path đó.
Query chậm, transaction dài và leak: ba thứ này liên quan nhau thế nào?
Team hay cố tách chúng ra, nhưng production thì chúng đè lên nhau.
- Query chậm làm connection bị chiếm lâu hơn.
- Transaction dài giữ connection lâu hơn cả query đơn lẻ.
- Leak làm một phần connection không quay về pool đúng nhịp.
Khi ba thứ cộng lại, pool exhaustion xảy ra nhanh hơn nhiều.
Ví dụ một endpoint làm như sau:
- bắt đầu transaction;
- đọc vài bảng;
- gọi một service ngoài để lấy thông tin bổ sung;
- chờ 600ms vì upstream chậm;
- quay lại update DB;
- commit.
Nếu connection được giữ suốt thời gian chờ upstream, mỗi request đang “chiếm ghế” trong pool lâu hơn nhiều so với nhu cầu SQL thật. Dưới load, đây là công thức rất nhanh để cạn pool mà không cần một leak “kinh điển”.
Transaction scope quá rộng là anti-pattern phổ biến nhất
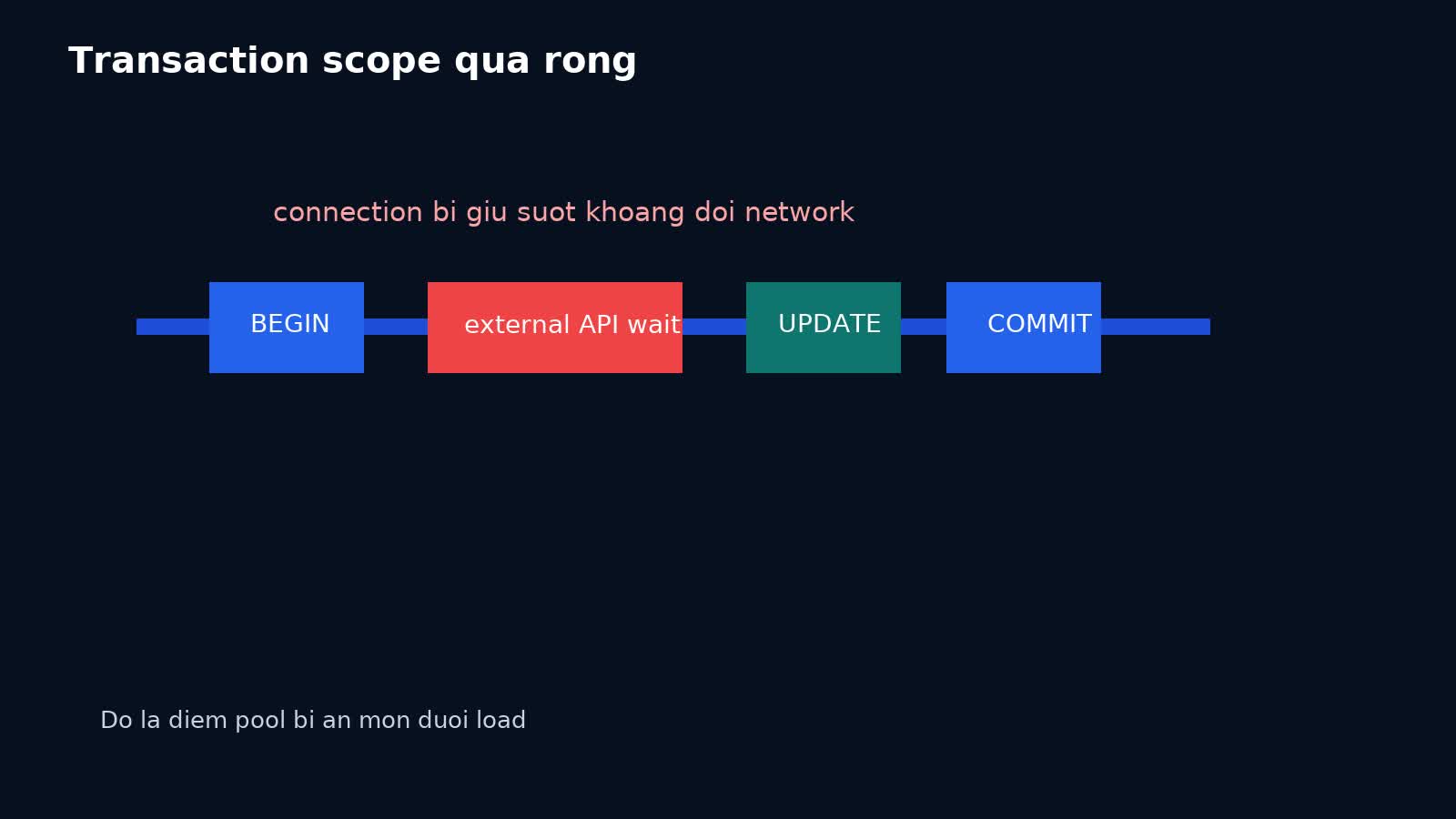
Nhiều incident không phải do quên close(), mà do giữ transaction qua những đoạn không cần DB.
Các ví dụ rất hay gặp:
- mở transaction rồi gọi HTTP sang service khác;
- mở transaction rồi publish event theo kiểu đồng bộ tự chế;
- giữ transaction khi render template/export file;
- làm vòng lặp xử lý 500 item trong cùng transaction dù mỗi item có thể commit nhỏ hơn;
- đọc large result set rồi xử lý business logic nặng trước khi release.
Nguyên tắc thực dụng là: connection chỉ nên bị giữ khi thật sự đang làm việc với database. Nếu code đang chờ network, sleep, retry, serialize dữ liệu lớn, hoặc đợi lock ngoài DB, đó là lúc nên tự hỏi tại sao connection vẫn còn trong tay.
ORM/session lifecycle là nguồn leak âm thầm
ORM giúp dev đi nhanh, nhưng nó cũng che bớt việc connection được mở/giữ/đóng ra sao.
Các bẫy thường gặp:
Session gắn sai scope
Session đáng lẽ sống trong một request hoặc một unit-of-work, nhưng lại gắn vào object sống lâu hơn như singleton service, async worker reused context, hoặc middleware chain khó nhìn.
Lazy loading sau khi tưởng đã xong
Code tưởng như chỉ đọc một object rồi serialize response. Nhưng trong lúc render, ORM lazy-load thêm association, kéo session/connection sống lâu hơn dự kiến.
Auto-transaction khó thấy
Một số framework mở transaction mặc định quanh request hoặc quanh block helper. Nếu team không hiểu rõ, họ dễ vô tình nhét I/O ngoài DB vào giữa transaction.
Exception path thiếu cleanup
Không phải framework nào cũng cứu được mọi path. Nếu custom middleware/job wrapper viết thiếu cleanup, connection vẫn có thể bị giữ lại lâu hơn nên có.
PgBouncer có cứu được không, hay chỉ làm symptom đổi hình?
PgBouncer rất hữu ích, nhưng không phải thuốc thần.
Nếu bài toán là quá nhiều client connection tới PostgreSQL, PgBouncer giúp multiplex và giảm overhead kết nối. Bài này nối rất hợp với bài về <a href="https://softwareengineer.vn/postgresql-connection-pooling-pgbouncer-production/">PgBouncer trong production</a>.
Nhưng nếu application giữ transaction quá lâu hoặc leak session ở tầng app, PgBouncer không sửa được logic đó. Nó có thể:
- làm symptom đến muộn hơn;
- giúp DB đỡ chết vì connection storm;
- nhưng vẫn để app timeout khi pool phía application hoặc transaction pool bị nghẹt.
Đặc biệt với transaction pooling mode, team phải hiểu rõ framework/ORM của mình có tương thích không. Nếu app ngầm phụ thuộc session state hoặc prepared statement theo kết nối, việc thêm PgBouncer mà không hiểu contract có thể tạo lỗi kiểu khác.
Pool size không phải cứ tăng là xong
Khi thấy pool timeout, phản xạ phổ biến là tăng pool từ 20 lên 50 hoặc 100. Tôi xem đây là một trong những cách nhanh nhất để đẩy vấn đề sang nơi đắt hơn.
Vì sao?
- Nếu root cause là leak, pool to hơn chỉ làm incident đến chậm hơn.
- Nếu query chậm, thêm connection có thể làm DB tranh chấp nặng hơn.
- Nếu app instances nhiều, mỗi instance tăng pool size có thể đập nát
max_connectionsphía database. - Nếu transaction giữ lock lâu, thêm concurrency chỉ làm lock contention xấu hơn.
Pool sizing phải được nhìn theo toàn hệ thống:
- số instance app;
- số worker/process/thread mỗi instance;
- mức concurrency thực tế;
- database max connections;
- có PgBouncer hay không;
- workload chủ yếu read, write hay mixed.
Tăng pool có thể là bước giảm cháy tạm thời, nhưng không nên là chẩn đoán.
Connection leak hay xuất hiện mạnh sau deploy và shutdown lỗi
Một case rất khó chịu là hệ thống chỉ nổ sau deploy, autoscaling hoặc restart rolling.
Vì sao?
- instance cũ chưa shutdown sạch, vẫn giữ connection/transaction dở dang;
- instance mới warm up tạo thêm load DB;
- worker nền tiếp tục nhận job dù đang trong quá trình drain;
- request in-flight không được cắt đúng, giữ connection lâu hơn bình thường.
Nếu service không có shutdown discipline tốt, pool exhaustion có thể bị khuếch đại mỗi lần rollout. Đây là chỗ bài <a href="https://softwareengineer.vn/graceful-shutdown-backend-kubernetes-production/">graceful shutdown trên Kubernetes</a> liên quan trực tiếp: ngừng nhận traffic, drain in-flight work, đóng DB resources tử tế trước khi process chết.
Observability: cần đo gì để không debug bằng niềm tin?

Tối thiểu tôi muốn có các metric và log sau:
1. Pool metrics
- pool size cấu hình;
- số connection active;
- số idle;
- số request đang chờ acquire;
- acquire wait time p50/p95/p99;
- timeout count khi acquire.
2. Transaction / query timing
- transaction duration p95/p99;
- query duration theo endpoint/job;
- count transaction mở quá ngưỡng;
- lock wait nếu DB expose được.
3. Request correlation
- endpoint nào hay chạm pool timeout nhất;
- request id / trace id nối được từ HTTP span sang DB span;
- variant deploy/canary nào bị nặng hơn.
4. Lifecycle logging có chọn lọc
Không phải log mọi lần acquire/release trong production nóng, nhưng nên có khả năng bật diagnostic mode để biết:
- ai mượn connection;
- mượn lúc nào;
- giữ bao lâu;
- release ở đâu;
- path exception nào không release đúng.
Nếu làm tracing tốt, anh sẽ nhìn thấy request spend 40ms query nhưng chờ 900ms để acquire connection. Đây là insight rất khác với “database chậm”.
Một flow debug thực dụng khi pool đang cháy
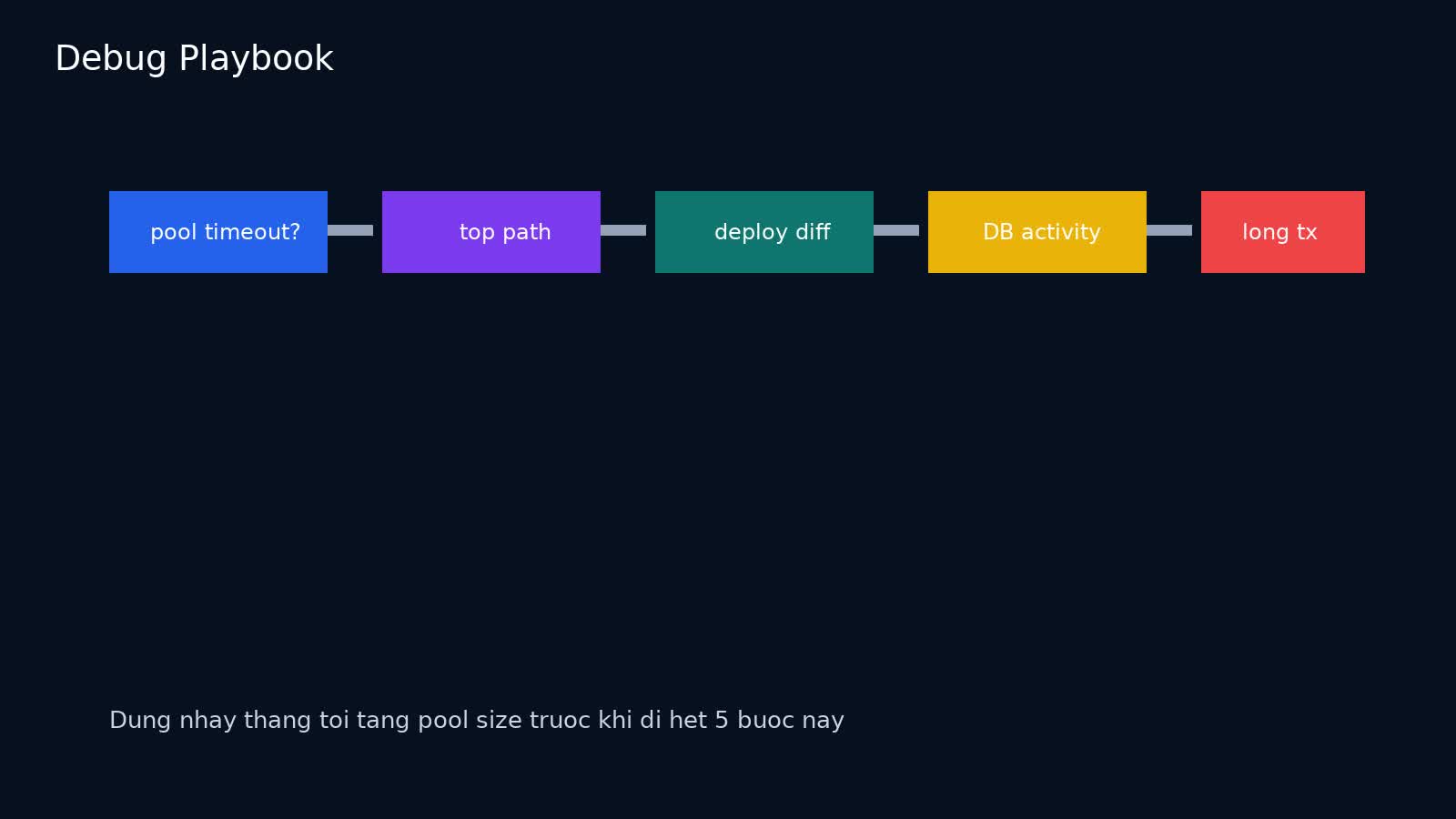
Khi incident đang diễn ra, tôi thường đi theo thứ tự này:
Bước 1: xác nhận đây là acquire problem hay DB execution problem
Nếu lỗi/log chủ yếu là timeout chờ pool, đó là tín hiệu rõ. Nếu query execution cũng tăng đồng loạt, cần xem cả DB saturation.
Bước 2: tìm top endpoint/job theo acquire wait và active transaction duration
Đừng nhìn trung bình toàn hệ thống. Thường chỉ vài path là thủ phạm chính.
Bước 3: đối chiếu deploy gần nhất
Nhiều leak đến từ refactor middleware, transaction wrapper, ORM session scope hoặc thêm một call ra external service giữa transaction. Canary metrics rất hữu ích ở đây; nếu chỉ version mới bị burn acquire wait, khoanh vùng nhanh hơn nhiều. Bài <a href="https://softwareengineer.vn/canary-release-backend-production/">canary release</a> đáng nối ở đoạn này.
Bước 4: kiểm tra app-side queue và DB-side activity cùng lúc
Nếu app chờ acquire dài nhưng DB query activity không quá khủng, nghi pool/lifecycle mạnh hơn. Nếu DB có nhiều idle-in-transaction session, nghi transaction scope hoặc cleanup path.
Bước 5: tìm long-lived transaction / idle in transaction
Với PostgreSQL, các session idle in transaction hoặc transaction age cao là vàng cho điều tra. Chúng không phải lúc nào cũng là leak thật sự, nhưng gần như luôn chỉ ra một thiết kế giữ connection quá lâu.
Ví dụ code: khác biệt giữa giữ connection quá lâu và tách scope đúng
Anti-pattern
async function createOrder(input: CreateOrderInput) {
const tx = await db.begin();
try {
const customer = await tx.customer.findById(input.customerId);
const fraud = await fraudClient.score(input); // giữ transaction trong lúc chờ network
if (fraud.blocked) {
await tx.rollback();
return { status: 'blocked' };
}
const order = await tx.order.insert({ ...input, riskScore: fraud.score });
await tx.commit();
return order;
} catch (err) {
await tx.rollback();
throw err;
}
}Tách scope tốt hơn
async function createOrder(input: CreateOrderInput) {
const fraud = await fraudClient.score(input);
if (fraud.blocked) {
return { status: 'blocked' };
}
return db.transaction(async (tx) => {
const customer = await tx.customer.findById(input.customerId);
return tx.order.insert({ ...input, riskScore: fraud.score, customerTier: customer.tier });
});
}Điểm quan trọng không phải style code đẹp hơn, mà là thời gian cầm connection ngắn hơn và dễ reason hơn.
Khi nào cần nghi lock contention chứ không chỉ leak?
Pool exhaustion đôi khi là hậu quả thứ cấp của lock contention.
Ví dụ:
- một transaction update batch lớn giữ row/table lock lâu;
- các transaction khác xếp hàng chờ lock;
- mỗi request chờ lock vẫn giữ connection;
- pool cạn dần;
- request mới không lấy nổi connection nữa.
Lúc này symptom ở app trông giống leak, nhưng gốc có thể là write path, migration, hoặc batch job gây lock. Bài <a href="https://softwareengineer.vn/postgresql-mvcc-vacuum-bloat-production/">MVCC, VACUUM và bloat</a> cũng liên quan vì churn lớn và transaction dài rất dễ kéo theo lock/wait bất thường.
Guardrail nào nên có để incident khó lặp lại?
Timeout rõ ràng
- acquire timeout phải hữu hạn;
- query timeout phải hữu hạn;
- transaction timeout nếu stack hỗ trợ;
- không để request treo vô thời hạn trong hàng chờ pool.
Timeout không sửa gốc rễ, nhưng nó ngăn một request kẹt mãi và tạo hiệu ứng domino.
Concurrency cap cho background jobs
Rất nhiều lần web traffic không phải thủ phạm, mà là worker queue hoặc backfill job lấy hết pool. Giới hạn concurrency theo queue/job class đáng giá hơn là tăng pool mù quáng.
Tách read/write pool khi phù hợp
Một số hệ thống benefit từ tách pool cho background/reporting path khỏi request path chính, để một batch job không hút sạch toàn bộ connection của API.
Alert theo acquire wait, không chỉ theo DB CPU
Nếu chỉ alert theo CPU database, team sẽ biết quá muộn hoặc không biết gì cả ở những incident pool-layer.
Checklist review code để chặn leak từ sớm
Khi review PR backend, tôi muốn hỏi ít nhất:
- Có mở transaction rồi gọi network/file/cache chậm ở giữa không?
- Có path exception/return sớm nào bỏ qua cleanup không?
- Có stream/cursor/result set nào cần close rõ ràng không?
- Session/ORM context sống trong phạm vi nào?
- Job mới có thể fan-out concurrency quá mức không?
- Có thêm instance/worker nhưng chưa tính tổng connection budget toàn hệ thống không?
- Shutdown path có ngừng nhận việc mới trước khi close DB resources không?
Kết luận
Connection leak và pool exhaustion là kiểu sự cố làm hệ thống chết chậm và khiến người debug nhìn sai tầng. Database có thể chưa sập, query đơn lẻ có thể vẫn nhanh, nhưng application đã mất khả năng mượn connection để phục vụ request tử tế.
Điều đáng sợ nhất không phải là một bug close() bị quên duy nhất. Thường đó là tổng hợp của transaction scope quá rộng, ORM lifecycle khó thấy, worker concurrency quá tay, lock contention, deploy/shutdown chưa sạch, và thiếu observability ở lớp pool.
Nếu phải ưu tiên ba việc có đòn bẩy cao nhất, tôi sẽ làm:
- đo acquire wait và transaction duration như metric hạng nhất;
- rút ngắn transaction scope, đặc biệt loại bỏ I/O ngoài DB ở giữa;
- review lại connection budget toàn hệ thống thay vì tăng pool theo cảm giác.
<section class="internal-links"><h2 id="doc-tiep-trong-cluster-backend-production">Đọc tiếp trong cluster backend production</h2><ul>
<li><a href="/postgresql-connection-pooling-pgbouncer-production/">PostgreSQL Connection Pooling với PgBouncer</a></li>
<li><a href="/graceful-shutdown-backend-kubernetes-production/">Graceful Shutdown cho Backend trên Kubernetes</a></li>
<li><a href="/canary-release-backend-production/">Canary Release trong Backend Production</a></li>
<li><a href="/postgresql-mvcc-vacuum-bloat-production/">PostgreSQL MVCC, VACUUM và table bloat</a></li>
<li><a href="/circuit-breaker-backend-production/">Circuit Breaker trong Backend Production</a></li>
<li><a href="/read-after-write-consistency-replica-lag-production/">Read-after-write consistency và replica lag</a></li>
</ul></section>