Dead Letter Queue trong Event-Driven Systems: poison message, retry budget và replay an toàn
Khi team mới làm event-driven architecture, Dead Letter Queue thường được thêm vào rất sớm như một “sọt rác an toàn”: message xử lý lỗi quá nhiều lần thì đẩy sang DLQ, phần còn lại cứ chạy tiếp. Cách nghĩ đó nghe hợp lý, nhưng trong production thật, DLQ không phải thùng rác. Nó là một cơ chế containment cho failure mà nếu thiết kế hời hợt, chính nó sẽ che mất lỗi dữ liệu, làm trôi business event, hoặc biến replay thành một đợt side effect lặp hàng loạt.
Rất nhiều incident âm ỉ bắt đầu từ đây:
- consumer retry vô hạn cho một message không bao giờ xử lý được;
- team đẩy message sang DLQ nhưng không có owner hay playbook xử lý;
- replay toàn bộ DLQ sau khi “fix bug” rồi vô tình tạo duplicate charge, duplicate email hoặc write lệch state;
- metrics chỉ đo queue depth chung, không biết message hỏng vì schema drift, timeout downstream hay dữ liệu poison.
Bài này đi sâu vào DLQ dưới góc production engineering cho backend engineer: DLQ giải quyết bài toán gì, khi nào nên dùng, cách phân loại lỗi retryable vs non-retryable, thiết kế retry budget, metadata tối thiểu phải có, mô hình replay an toàn, observability nên đo, và những anti-pattern làm event pipeline trông có vẻ resilient nhưng thực ra chỉ giấu failure đi chỗ khác.
Dead Letter Queue thực chất là gì?
Dead Letter Queue là nơi chứa những message không thể được xử lý thành công trong lane chính sau khi đã đi qua policy retry đã định nghĩa trước.
Cụm “không thể được xử lý” rất quan trọng. Nó không có nghĩa là message đó vĩnh viễn vô dụng. Nó chỉ có nghĩa là tại thời điểm hiện tại, hệ thống quyết định:
- không tiếp tục retry trong hot path nữa;
- tách message lỗi ra khỏi luồng chính để bảo vệ throughput chung;
- giữ lại đầy đủ evidence để điều tra và xử lý sau.
Nếu retry vô hạn trên lane chính, một poison message có thể giữ worker bận liên tục, làm backlog phình ra và kéo latency của hàng nghìn message khỏe mạnh. DLQ tồn tại để ngăn failure cục bộ biến thành failure hệ thống.
DLQ giải quyết bài toán containment, không tự giải quyết bài toán correctness
Đây là ngộ nhận phổ biến nhất: có DLQ nghĩa là hệ thống “an toàn”. Không hẳn.
DLQ giúp containment ở ba điểm:
- cô lập message hỏng khỏi traffic bình thường;
- giữ worker không bị kẹt mãi vào một message thất bại;
- tạo điểm tập trung để điều tra nguyên nhân và replay có kiểm soát.
Nhưng DLQ không tự đảm bảo:
- business event cuối cùng sẽ được xử lý đúng;
- downstream side effect là idempotent;
- replay không gây duplicate action;
- team có ai chịu trách nhiệm dọn và xử lý DLQ.
Nói cách khác, DLQ làm hệ thống bớt vỡ dây chuyền, nhưng nếu không có ownership và replay discipline, nó chỉ chuyển lỗi từ runtime sang operations.
Khi nào nên đẩy message sang DLQ thay vì retry tiếp?
Không có một con số retry đúng cho mọi workload. Điều quan trọng là phân biệt hai nhóm lỗi.
1. Lỗi tạm thời, có khả năng tự hồi
Ví dụ:
- downstream API timeout ngắn hạn;
- database failover trong vài giây;
- rate limit tạm thời;
- network partition ngắn;
- dependency trả 503 trong lúc deploy.
Những lỗi này thường nên đi theo retry có backoff, jitter và deadline tổng.
2. Lỗi cấu trúc hoặc poison message
Ví dụ:
- schema không parse được;
- thiếu field bắt buộc;
- version event không tương thích với consumer hiện tại;
- business invariant không thể thỏa mãn, như order đã bị canceled từ trước nhưng message lại cố ship tiếp;
- dữ liệu tham chiếu bị hỏng;
- code bug deterministic: chạy lại 100 lần vẫn fail đúng chỗ đó.
Nhóm này càng retry càng tốn tài nguyên và làm queue bẩn hơn. Chính là lúc DLQ nên nhận message.
Poison message không phải lúc nào cũng là dữ liệu xấu
Nhiều team nghe “poison message” rồi nghĩ ngay tới payload bẩn. Thực tế poison message là bất kỳ message nào gây failure lặp lại mà policy retry trong lane chính không thể giải quyết hợp lý.
Một message có thể trở thành poison vì:
- payload vi phạm schema;
- payload hợp lệ nhưng code consumer có bug logic;
- thứ tự event làm state hiện tại không chấp nhận được;
- dependency idempotency yếu khiến replay tạo side effect conflict;
- migration dữ liệu dở dang khiến một tập entity không còn đúng assumption cũ.
Điểm cần nhớ là poison message là khái niệm vận hành, không chỉ là khái niệm validation.
Retry budget cho queue consumer: đừng để retry vô hạn vì “biết đâu lần sau được”

Tư duy retry budget trong event pipeline rất giống error budget ở production. Hệ thống cần biết mình sẵn sàng trả bao nhiêu chi phí compute, latency và backlog để theo đuổi một message lỗi trước khi tách nó ra.
Một retry policy thường nên có ít nhất:
- max attempts;
- delay/backoff theo bậc;
- jitter để tránh đồng bộ retry;
- total age deadline cho message;
- phân loại lỗi retryable / non-retryable.
Ví dụ policy thực dụng:
- lỗi parse schema: không retry, vào DLQ ngay;
- lỗi 4xx business invariant: retry 0-1 lần nếu có khả năng race, rồi vào DLQ;
- lỗi timeout/503: retry 5 lần với exponential backoff và total deadline 15 phút;
- sau khi quá retry budget hoặc quá age deadline: vào DLQ.
Điều này tốt hơn rất nhiều so với một rule ngây thơ kiểu “retry 10 lần cho mọi exception”.
Metadata tối thiểu một message trong DLQ phải mang theo
Nếu DLQ chỉ chứa payload gốc và gần như không có ngữ cảnh, team điều tra sẽ phải làm forensic từ log rời rạc. Đó là thiết kế tệ.
Mỗi message vào DLQ nên mang ít nhất:
- original topic / queue / subscription;
- event type và event version;
- message id hoặc idempotency key;
- aggregate id liên quan như order_id, user_id, invoice_id;
- first seen time, last attempted time;
- attempt count;
- error class;
- error message rút gọn;
- consumer/service name và version;
- trace id hoặc correlation id;
- snapshot của headers quan trọng;
- lý do route vào DLQ theo policy nào.
Metadata này biến DLQ từ “sọt rác” thành nguồn sự thật để debug và quyết định replay.
Một DLQ tốt luôn đi cùng classification rõ ràng
Không phải mọi message trong DLQ đều giống nhau. Nếu để tất cả trộn chung, team sẽ khó biết nên xử lý gì trước.
Một cách phân loại hữu ích:
Theo loại lỗi
- parse/schema error
- business rule violation
- downstream timeout
- auth/permission failure
- dependency unavailable
- code bug deterministic
Theo mức ảnh hưởng nghiệp vụ
- mất doanh thu
- chậm đồng bộ nội bộ
- notification không critical
- analytics/event phụ trợ
Theo replay safety
- safe to replay automatically
- requires idempotency check
- requires manual review
- never replay; needs data correction first
Khi có classification, team operations không phải đoán mò giữa hàng trăm message.
Anti-pattern rất phổ biến: replay toàn bộ DLQ sau khi fix bug
Đây là một trong những cách nhanh nhất để tạo incident thứ hai.
Giả sử team sửa một bug ở consumer order-paid, rồi bấm replay toàn bộ 50.000 message trong DLQ. Nếu downstream charge service, email service, inventory reservation hoặc CRM sync không thật sự idempotent, replay hàng loạt có thể gây:
- duplicate email;
- duplicate ledger write;
- reserve tồn kho hai lần;
- cập nhật state lùi/ngược do thứ tự event cũ.
Replay an toàn cần trả lời trước ba câu hỏi:
- Message này đã từng commit side effect nào chưa?
- Consumer hiện tại có idempotency guard ở đâu?
- Replay có cần giữ nguyên thứ tự theo aggregate không?
Nếu chưa trả lời được ba câu đó, replay hàng loạt là rất liều.
Replay an toàn nên được thiết kế như một workflow riêng
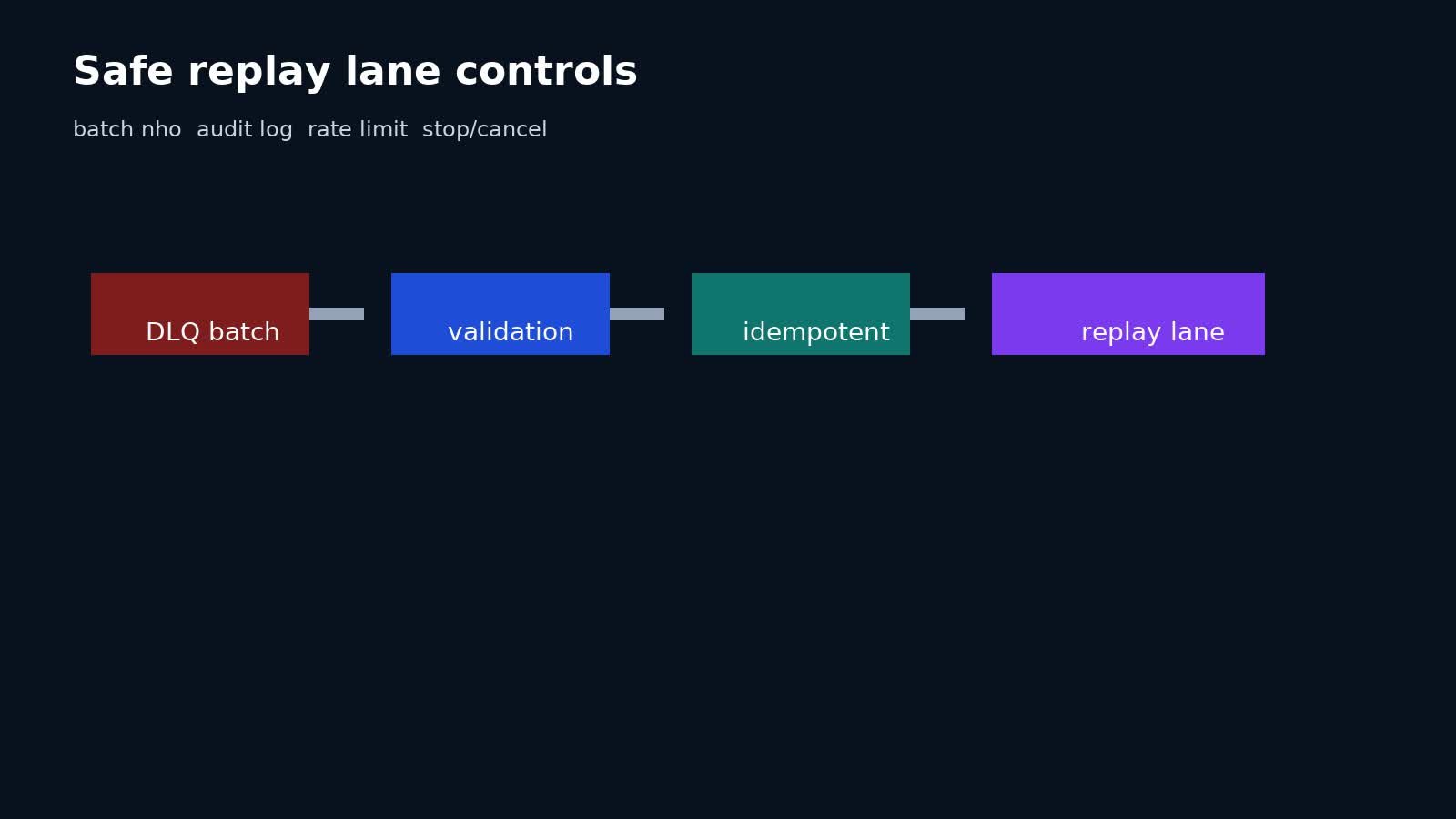
Đừng coi replay là “ném lại vào queue gốc và cầu nguyện”. Một workflow replay tốt thường có:
- batch size giới hạn;
- dry-run hoặc validation mode;
- filter theo error class / date range / consumer version;
- concurrency cap;
- idempotency enforcement;
- audit log cho ai replay, replay cái gì, kết quả ra sao;
- khả năng cancel/pause;
- lane riêng cho replay nếu workload nhạy cảm.
Hai chiến lược replay phổ biến
#### 1. Requeue trực tiếp về topic gốc
Hợp khi:
- consumer idempotent tốt;
- workload không cần ordering quá chặt;
- số lượng message ít;
- bug đã fix triệt để.
Rủi ro:
- cạnh tranh tài nguyên với traffic mới;
- message cũ chen vào state hiện tại theo cách khó đoán;
- dễ tái tạo backlog spike.
#### 2. Replay lane riêng hoặc tool điều phối riêng
Hợp khi:
- event quan trọng về tài chính/trạng thái đơn hàng;
- cần rate limit;
- cần giữ ordering theo aggregate;
- cần manual review trước khi replay.
Tôi thích chiến lược lane riêng hơn cho các workload có side effect thật, vì nó cho mình nhiều control hơn thay vì trộn replay với production hot path.
Ordering và idempotency: hai câu hỏi phải đặt trước cả lúc thiết kế DLQ
DLQ thường bị nghĩ là chuyện “xử lý lỗi sau này”, nhưng thực ra nó ép team nghĩ sớm về correctness.
Ordering
Nếu hệ thống yêu cầu event của cùng một aggregate phải theo thứ tự, replay sai thứ tự có thể làm state hỏng.
Ví dụ:
order_createdorder_paidorder_shippedorder_refunded
Nếu order_paid từng rơi vào DLQ nhưng order_shipped đã được xử lý bởi nhánh khác, replay muộn có thể đẩy state vào tình huống rất khó hiểu trừ khi consumer được thiết kế theo state machine rõ ràng.
Idempotency
Nếu consumer viết ra side effect bên ngoài như charge thẻ, gửi email, push webhook hoặc tạo ticket, replay mà không có idempotency key là mở cửa cho duplicate action.
DLQ không tạo idempotency thay cho anh. Nó chỉ phơi bày việc anh có nó hay không.
Mô hình decision tree thực dụng cho consumer failure
Một decision tree khá hữu ích:
- Parse/validation có pass không?
- Lỗi có retryable theo policy không?
- Message còn nằm trong total age budget không?
- Attempt count còn trong ngưỡng không?
- Dependency đang lỗi hệ thống diện rộng không?
- Nếu retry thành công, side effect có safe không?
- Không → DLQ ngay.
- Không → DLQ ngay.
- Không → DLQ.
- Không → DLQ.
- Có → backoff, shed load, có thể pause consumer hoặc giảm concurrency.
- Nếu không chắc → route qua lane manual review hoặc replay workflow có kiểm soát.
Điểm quan trọng là decision tree phải được mã hóa thành policy rõ ràng, không phải để mỗi team member tự diễn giải trong incident.
DLQ và observability: nếu chỉ nhìn queue depth thì gần như mù
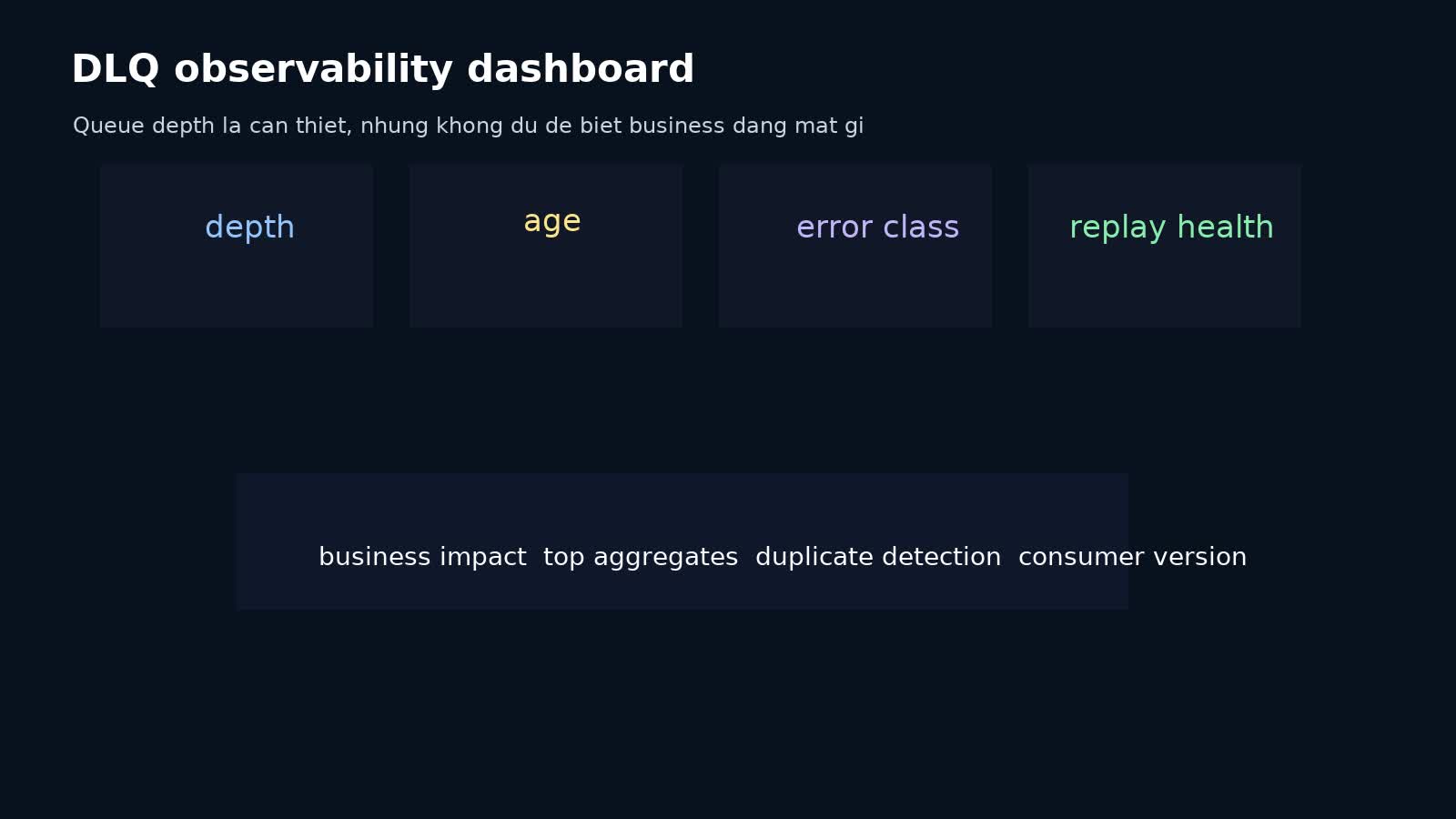
Queue depth là metric cần có, nhưng không đủ. Một DLQ có 50 message có thể vô hại hơn nhiều so với một DLQ có 5 message nhưng tất cả đều thuộc event thanh toán.
Những metric nên có:
Volume và tốc độ tăng
- số message mới vào DLQ theo phút/giờ;
- DLQ depth theo queue/topic;
- age distribution của message trong DLQ;
- top error class theo volume.
Chất lượng failure
- retry-to-success ratio;
- first-failure rate;
- non-retryable vs retryable breakdown;
- poison message by consumer version.
Tác động nghiệp vụ
- số aggregate bị ảnh hưởng;
- số order/user/invoice đang ở trạng thái pending vì event nằm trong DLQ;
- estimated revenue impact nếu có.
Replay health
- replay success rate;
- duplicate detection count;
- replay latency;
- số message quay lại DLQ sau replay.
Khi đo đủ mấy lớp này, team mới phân biệt được “DLQ đang giúp containment” với “DLQ đang âm thầm thành nghĩa địa event”.
Ví dụ policy pseudo-code cho queue consumer
async function handleMessage(msg: EventMessage) {
const meta = loadMeta(msg)
try {
validateSchema(msg)
} catch (err) {
return sendToDlq(msg, meta, { reason: 'schema_error', retryable: false, error: err })
}
if (meta.ageMs > MAX_AGE_MS) {
return sendToDlq(msg, meta, { reason: 'expired_retry_budget', retryable: false })
}
try {
await processBusinessLogic(msg)
return ack(msg)
} catch (err) {
if (!isRetryable(err)) {
return sendToDlq(msg, meta, { reason: classify(err), retryable: false, error: err })
}
if (meta.attempt >= MAX_ATTEMPTS) {
return sendToDlq(msg, meta, { reason: 'attempt_budget_exhausted', retryable: true, error: err })
}
return retryWithBackoff(msg, nextDelay(meta.attempt))
}
}Pseudo-code trên đơn giản nhưng thể hiện đúng tinh thần: validation, age budget, error classification, retry policy và DLQ route là một policy nhất quán, không phải những catch rời rạc.
Khi nào không nên dùng DLQ như giải pháp chính?
Có vài tình huống DLQ không phải trung tâm của thiết kế.
1. Workload cần đồng bộ mạnh theo transaction boundary
Nếu business flow yêu cầu commit đồng thời rất chặt, vấn đề có thể phải được giải bằng outbox pattern, saga coordination hoặc transactional guarantee ở lớp khác, không phải đẩy lỗi sang DLQ rồi xử lý sau.
2. Event không đáng giữ lại
Một số analytics hoặc telemetry event có giá trị thấp. Nếu xử lý thất bại sau vài lần và không có nhu cầu replay, lưu giữ vào DLQ quá lâu đôi khi chỉ làm tăng noise vận hành.
3. Team chưa có ai sở hữu DLQ
Nghe hơi ngược đời, nhưng DLQ không có owner thường tệ hơn việc fail rõ ràng. Ít nhất fail rõ ràng khiến mọi người cảm nhận được đau. DLQ vô chủ lại khiến lỗi biến mất khỏi mắt thường cho tới khi business hỏi vì sao dữ liệu lệch.
Runbook tối thiểu cho DLQ trong production
Nếu đang vận hành event pipeline thật, tôi muốn ít nhất một runbook như sau:
Phần detect
- alert khi DLQ ingress vượt baseline;
- alert khi có error class mới xuất hiện đột biến;
- alert khi message age vượt SLA đã định.
Phần triage
- xem top error class;
- xác định scope aggregate bị ảnh hưởng;
- kiểm tra consumer version gần nhất;
- đối chiếu deployment, schema change, downstream incident.
Phần decide
- fix code trước hay sửa dữ liệu trước;
- replay tự động, replay lane riêng hay manual intervention;
- có cần dừng consumer hoặc giảm concurrency tạm thời không.
Phần recover
- replay theo batch nhỏ;
- theo dõi duplicate và failure loop;
- xác nhận business state đã khớp lại;
- viết postmortem nếu impact đáng kể.
Những câu hỏi đáng tự audit ngay hôm nay
- Team có phân biệt retryable và non-retryable error thật sự chưa?
- Message vào DLQ có đủ metadata để debug không?
- Có ai chịu trách nhiệm dọn và review DLQ hằng ngày/tuần không?
- Replay hiện tại có audit log, rate limit và idempotency check không?
- Có dashboard nào cho business impact của DLQ không, hay chỉ có số lượng message?
- Có message nào đang nằm trong DLQ hàng tuần mà chưa ai hiểu nguyên nhân không?
Nếu phần lớn câu trả lời là “chưa”, DLQ của anh đang là một vùng rủi ro bị trì hoãn, không phải một control plane trưởng thành.
Kết luận
Dead Letter Queue là cơ chế rất hữu ích trong event-driven systems, nhưng nó chỉ phát huy giá trị khi được thiết kế như một phần của reliability policy hoàn chỉnh: có retry budget, có error classification, có metadata tốt, có replay discipline, có observability và có owner thật.
Điều tôi lo nhất không phải hệ thống không có DLQ. Điều tôi lo là hệ thống có DLQ nhưng coi đó là bằng chứng của resilience trong khi thực tế chỉ đang giấu failure khỏi lane chính. Một DLQ tốt không làm lỗi biến mất; nó làm lỗi trở nên cô lập, nhìn thấy được và xử lý được mà không phá phần còn lại của hệ thống.
Nếu phải chọn ba việc nên làm đầu tiên, tôi sẽ làm:
- chặn retry vô hạn bằng retry budget rõ ràng;
- thêm metadata + classification tử tế cho message vào DLQ;
- thiết kế replay workflow an toàn trước khi incident đầu tiên buộc mình phải replay trong hoảng loạn.