Queue-Based Load Leveling trong Backend Production: dùng queue để hạ đỉnh tải mà không che giấu bottleneck
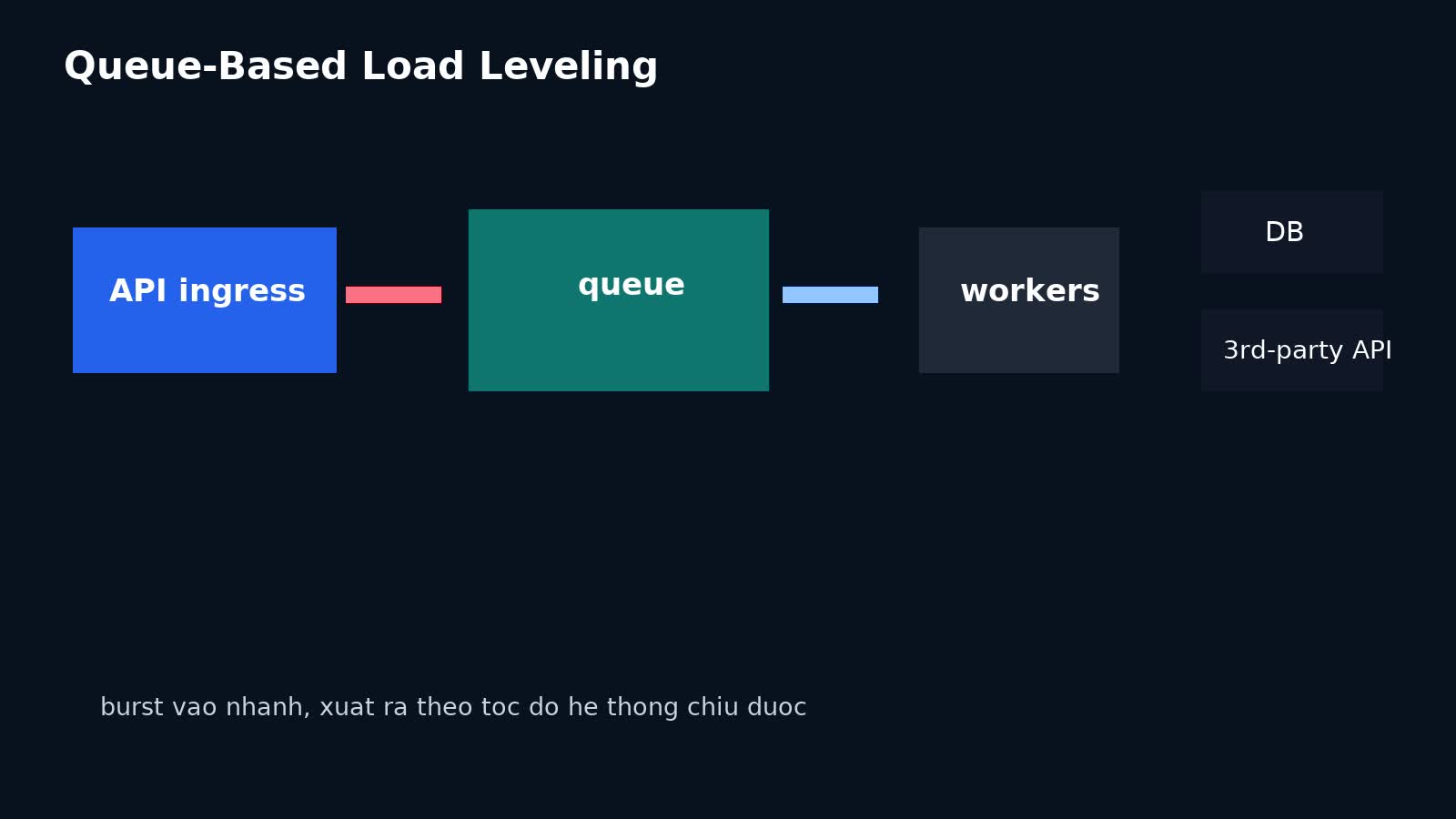
TL;DR: Queue-based load leveling không phải “ném hết vào queue là xong”. Nó là kỹ thuật dùng hàng đợi làm buffer giữa ingress và worker/downstream để hấp thụ burst traffic, giới hạn concurrency, bảo vệ dependency và đổi một phần latency đồng bộ lấy độ ổn định hệ thống. Nếu làm sai, queue chỉ biến overload trực tiếp thành backlog âm thầm, timeout dây chuyền và SLA vỡ chậm hơn.
Vì sao backend production hay chết ở peak ngắn chứ không chết ở load trung bình?
Nhiều hệ thống nhìn ổn ở p50 nhưng lại gãy ở vài phút cao điểm: campaign vừa mở, cron chạy đồng loạt, webhook đổ về cùng lúc, partner retry sau lỗi mạng, hoặc người dùng bấm lại vì UI chưa phản hồi. Vấn đề không chỉ là nhiều request hơn. Vấn đề là các request đó cùng tranh:
- connection pool đến database
- worker thread/process
- rate limit của third-party API
- CPU cho serialization hoặc encryption
- lock contention trên cùng aggregate hoặc cùng bảng nóng
Khi request đồng bộ đẩy thẳng vào dependency chậm, hệ thống thường đi qua chuỗi suy sụp quen thuộc:
- latency tăng
- request giữ connection lâu hơn
- queue trong app server hoặc load balancer dài ra
- retry từ client và upstream làm tải tăng thêm
- pool cạn, timeout lan sang các route khác
- team nhìn dashboard và thấy “mọi thứ chết dần” chứ không nổ ngay
Nếu bài toán của anh là công việc có thể xử lý bất đồng bộ, queue-based load leveling là một trong những cách thực dụng nhất để cắt đỉnh tải và giữ service xử lý ở tốc độ mà downstream chịu được.
Queue-based load leveling là gì?
Theo Azure Architecture Center, đây là pattern dùng queue như một buffer giữa bên tạo việc và bên xử lý việc để làm mượt các đợt tải tăng đột ngột. Ý chính không phải queue tự làm hệ thống nhanh hơn. Ý chính là:
- ingress nhận yêu cầu nhanh hơn
- request không ép downstream xử lý ngay lập tức
- worker kéo việc ra với tốc độ được kiểm soát
- hệ thống đổi peak đồng bộ thành backlog có quan sát được
Một flow tối giản:
- API nhận request tạo việc
- validate và persist job/message
- trả về
202 Acceptedhoặc trạng thái đã nhận - worker đọc queue theo concurrency budget cố định
- worker gọi dependency, ghi DB, cập nhật trạng thái job
- client poll status, nhận webhook callback hoặc xem eventual result
Pattern này đặc biệt hợp với:
- export report
- gửi email/SMS/push hàng loạt
- xử lý media, OCR, indexing
- webhook ingestion cần decouple khỏi business processing
- sync dữ liệu sang third-party chậm hoặc bị rate limit
- pipeline event-driven có workload bursty
Nó không hợp với mọi API. Nếu người dùng bắt buộc cần kết quả ngay trong request-response cycle, queue không xóa được ràng buộc latency đó. Nó chỉ chuyển bài toán sang thiết kế async UX hoặc workflow khác.
Queue giúp được gì, và không giúp được gì?
Queue giúp
- Absorb burst: traffic vào tăng nhanh nhưng worker vẫn giữ throughput ổn định.
- Bảo vệ dependency: giới hạn số tác vụ chạm DB, cache, search cluster hay third-party API cùng lúc.
- Tách tốc độ producer/consumer: bên nhận việc và bên xử lý việc không cần scale cùng nhịp.
- Cho phép retry có kiểm soát: lỗi tạm thời có thể backoff thay vì bắt client retry mù.
- Tạo điểm quan sát rõ: backlog, age, processing rate, retry rate, dead-letter rate.
Queue không giúp
- không sửa được code xử lý chậm hoặc query tệ
- không tạo thêm capacity thật cho downstream
- không giải quyết thứ tự nghiệp vụ nếu consumer model sai
- không tự động chống duplicate processing
- không cứu được hệ thống nếu producer đẩy việc nhanh hơn khả năng xử lý quá lâu
Đây là điểm nhiều team tự lừa mình: sau khi thêm queue, API thôi timeout nên tưởng đã “fix scale”. Thực ra chỉ là đổi user-facing failure ngay lập tức thành backlog tăng âm thầm. Nếu không có SLO cho queue lag và age, incident sẽ quay lại dưới dạng khác.
Khi nào nên chọn queue-based load leveling?
Hãy cân nhắc pattern này khi có đủ ba dấu hiệu:
1. Công việc có thể bất đồng bộ về mặt nghiệp vụ
Ví dụ:
- tạo invoice PDF không cần trả PDF ngay trong request
- webhook từ payment gateway chỉ cần ack sớm rồi xử lý sau
- email chào mừng không cần block signup response
- sync CRM không nên kéo chậm transaction chính
2. Downstream có giới hạn throughput rõ ràng
Ví dụ:
- PostgreSQL bắt đầu pool exhaustion khi >N concurrent writes nặng
- Elasticsearch ingest bị choke khi bulk quá dày
- third-party API có hard rate limit
- service nội bộ bị overload khi nhiều request cùng gọi endpoint đắt
3. Backlog là trade-off chấp nhận được hơn timeout đồng bộ
Nếu anh chấp nhận:
- xử lý chậm thêm vài giây/phút trong peak
- trả trạng thái “đã nhận xử lý”
- eventual consistency ở một số bước
thì queue là cách đổi failure mode thường rất đáng giá.
Thiết kế flow ingest đúng: đừng đưa nửa transaction vào queue
Một anti-pattern phổ biến là:
- API nhận request
- gọi third-party hoặc ghi business side effect ngay
- rồi mới enqueue một message phụ để “theo dõi”
Cách đó không hề decouple phần nặng nhất. Nếu request đã block ở điểm đắt, queue chỉ là phụ kiện.
Một flow chắc hơn thường là:
- validate input
- ghi record job hoặc business intent bền vững trong DB
- enqueue message cùng idempotency key / job id
- commit
- trả response ngay
Nếu cần vừa ghi DB vừa tạo message một cách nhất quán, nên nối với Transactional Outbox thay vì publish queue kiểu best-effort. Queue-based load leveling và outbox thường đi cùng nhau: một cái hấp thụ tải, một cái giữ đúng tính nhất quán producer-side.

Đừng nhầm queue length với health
Queue dài không phải lúc nào cũng xấu. Queue rỗng không phải lúc nào cũng tốt.
Điều cần nhìn là:
- arrival rate: job đến bao nhiêu/giây
- processing rate: worker xử lý bao nhiêu/giây
- oldest message age: job cũ nhất nằm chờ bao lâu
- time-to-drain: nếu dừng producer, cần bao lâu để xả hết backlog
- retry amplification: một job lỗi có tạo thêm bao nhiêu attempt
Ví dụ:
- backlog 20.000 job có thể ổn nếu mỗi job nhẹ và drain trong 4 phút
- backlog 500 job có thể cực xấu nếu oldest age đã 25 phút và SLA chỉ cho 2 phút
Health của queue phải gắn với SLO nghiệp vụ, không chỉ con số depth tuyệt đối.
Giới hạn concurrency ở worker mới là trái tim của pattern
Queue không tự bảo vệ downstream nếu worker scale vô tội vạ. Nhiều hệ thống thêm queue rồi autoscale consumer theo backlog quá hung hăng, kết quả là chính worker bắn tải ồ ạt vào DB hoặc API đích và làm nghẽn mạnh hơn trước.
Worker nên có các guardrail:
-
max_concurrencyrõ cho từng loại job - per-dependency semaphore hoặc pool budget
- batch size hợp lý, không càng to càng tốt
- rate limiting theo tenant hoặc theo partner nếu cần fairness
- backoff khi dependency chậm hoặc trả 429/5xx
- circuit breaker/load shedding nếu downstream đang vào vùng nguy hiểm
Nói cách khác: queue chỉ là buffer. Concurrency policy mới quyết định anh xả buffer như thế nào.
Mô hình dữ liệu job/queue nên có gì?
Nếu anh dùng queue thuần của broker, vẫn nên có state rõ ở application layer. Một record job điển hình có thể gồm:
job_idjob_type-
tenant_idhoặcpartition_key -
status: pending / processing / succeeded / failed / dead_lettered attempt_countnext_attempt_at-
payload_refhoặc payload hash created_atstarted_atfinished_atlast_erroridempotency_key
Với workload nặng, đừng nhét payload lớn vào message nếu không cần. Hãy cân nhắc:
- message chỉ chứa reference id
- payload chính nằm ở DB/object storage
- worker load lại dữ liệu theo snapshot hoặc version phù hợp
Cách này giúp broker nhẹ hơn, retry rẻ hơn, và schema evolution dễ kiểm soát hơn.
Ordering, fairness và head-of-line blocking
Queue nghe đơn giản nhưng khi vào production thường lòi ra ba bài toán khó.
Ordering
Không phải job nào cũng cần global ordering. Nếu cố ép toàn hệ thống FIFO, throughput sẽ tụt rất nhanh. Câu hỏi đúng là:
- có cần ordering theo tenant?
- theo account?
- theo aggregate id?
- hay hoàn toàn không cần?
Thường chỉ cần partitioned ordering trên một business key nào đó.
Fairness
Một tenant lớn có thể nuốt hết worker nếu queue dùng chung mà không có quota. Kết quả là tenant nhỏ bị starvation dù tổng hệ thống vẫn “healthy”.
Giải pháp tùy mức độ phức tạp:
- queue riêng theo workload/priority
- partition key theo tenant
- weighted fair scheduling
- rate limit theo tenant ở consumer
Head-of-line blocking
Một message poison hoặc một job rất nặng có thể giữ lane quá lâu. Nếu workload không đồng nhất, nên tách:
- fast lane / slow lane
- realtime-ish / batch
- CPU-bound / IO-bound
- high priority / normal priority
Không phải cứ một queue chung là đơn giản hơn. Rất nhiều sự cố production đến từ việc dồn mọi thứ vào cùng một pipeline vì “dễ quản lý”.
Retry đúng cách: queue làm lỗi to lên rất nhanh nếu retry mù
Retry là chỗ queue biến lỗi nhỏ thành bão tài nguyên nếu làm sai.
Retry nên có
- exponential backoff
- jitter
- max attempts
- phân loại retryable vs non-retryable
- dead-letter queue hoặc parking lot cho case cần điều tra
Retry không nên
- retry ngay lập tức nhiều lần liên tiếp
- mọi exception đều retry như nhau
- nhiều tầng cùng retry: client, producer, worker, SDK cùng nhân tải
- retry vô hạn với payload hỏng dữ liệu
Một công thức thực tế hơn là:
- lỗi validate/business invariant: fail nhanh, không retry
- lỗi 429/503/network timeout: retry có backoff
- lỗi dependency quá tải: giảm concurrency trước rồi mới retry
Nếu team đã từng gặp duplicate processing, hãy nhớ queue retry không thể tách rời idempotent consumer. Worker có thể commit side effect xong nhưng crash trước khi ack; broker sẽ redeliver. Nếu consumer không idempotent, một chiến lược retry tốt vẫn gây sai business state.

Kết hợp queue với load shedding và admission control
AWS Builders’ Library nhấn mạnh một ý rất thật: khi hệ thống đã vào vùng overload, cần biết từ chối bớt công việc thay vì cố nhận hết rồi chết cùng nhau.
Với queue-based load leveling, điều này dẫn đến ba lớp phòng thủ:
1. Admission control ở ingress
Nếu backlog đã vượt ngưỡng, có thể:
- trả
429 Too Many Requests - chỉ nhận traffic ưu tiên cao
- reject một số job type không thiết yếu
- degrade tính năng phụ
2. Bounded queue
Queue vô hạn nghe tiện nhưng dễ giấu incident. Bounded queue buộc team phải đối diện capacity thật. Khi đầy, hệ thống phải có policy rõ:
- reject
- drop loại việc không quan trọng
- spill sang batch/later window
- chuyển sang region/pipeline khác nếu có
3. Load shedding ở consumer/downstream
Nếu dependency đang meltdown, worker phải hạ concurrency hoặc dừng gọi một lớp tác vụ nào đó. Nếu không, queue chỉ làm “ống tăng áp” đưa nhiều việc hơn vào nơi đang nghẹt.
Queue-based load leveling khác gì cache, rate limit, bulkhead, circuit breaker?
Đây là các lớp khác nhau, không thay thế nhau.
- Rate limit: chặn bớt lưu lượng ngay từ đầu.
- Queue-based load leveling: buffer và dàn tải theo thời gian.
- Bulkhead: cô lập tài nguyên để lane này chết không kéo lane khác.
- Circuit breaker: ngừng gọi dependency đang lỗi nặng.
- Cache: giảm số lần phải chạm dependency cho workload đọc.
Một kiến trúc production khỏe thường dùng nhiều lớp cùng lúc. Ví dụ:
- ingress rate limit chống abuse
- queue để absorb burst hợp lệ
- worker bulkhead theo job type
- circuit breaker quanh third-party API
- idempotent consumer cho retry/redelivery

Một ví dụ production thực tế: webhook ingestion
Webhook là nơi pattern này rất hợp.
Flow tệ
- nhận webhook
- verify signature
- gọi DB nhiều bước
- gọi API nội bộ/ngoài
- mới trả
200
Nếu downstream chậm, provider timeout rồi retry. Hệ thống nhận duplicate burst đúng lúc đang yếu nhất.
Flow tốt hơn
- nhận webhook
- verify signature và validate tối thiểu
- persist raw event + idempotency key
- enqueue job xử lý
- trả
200sớm - worker xử lý business logic với concurrency budget riêng
Từ đó, provider không phải giữ connection lâu, còn team có thể quan sát backlog và retry tách biệt với latency của endpoint ingress.
Các metric bắt buộc nếu không muốn queue thành black hole
Tối thiểu nên có:
- queue depth
- oldest message age
- processing throughput
- success rate / failure rate
- retry rate theo reason
- dead-letter count
- consumer lag theo partition/subscriber nếu broker hỗ trợ
- worker concurrency hiện tại
- downstream latency/error rate tương quan theo job type
- time from enqueue to completion theo p50/p95/p99
Nên có thêm breakdown theo:
- tenant
- priority
- job type
- dependency bị gọi
Incident thực tế thường không đến từ “queue tăng”, mà từ việc một lane cụ thể bị kẹt trong khi dashboard tổng vẫn trông bình thường.
Những ngộ nhận rất hay gặp
“Thêm queue là scale được”
Sai. Queue chỉ tách producer khỏi consumer. Năng lực xử lý cuối cùng vẫn phụ thuộc worker, DB, network, dependency và correctness model.
“Backlog tăng tức là cần autoscale mạnh hơn”
Chưa chắc. Nếu bottleneck nằm ở DB hoặc third-party API, scale worker mạnh hơn chỉ đẩy hệ thống vào overload nhanh hơn.
“Dùng FIFO là an toàn nhất”
Không phải. FIFO rộng toàn hệ thống thường giết throughput và tăng coupling nghiệp vụ. Chỉ giữ ordering ở scope thật sự cần.
“Có queue rồi thì không cần rate limit”
Sai. Queue vẫn cần admission control. Nếu producer vượt xa capacity trong thời gian dài, backlog sẽ thành nợ không trả nổi.
“Retry nhiều sẽ eventually thành công”
Sai trong overload. Retry mù thường làm dependency chết kỹ hơn.
Checklist áp dụng queue-based load leveling cho backend production
- [ ] Xác định rõ bước nào có thể async về mặt nghiệp vụ
- [ ] Định nghĩa SLO cho enqueue-to-complete time, không chỉ request latency
- [ ] Giữ job record hoặc trạng thái nghiệp vụ quan sát được
- [ ] Chọn scope ordering nhỏ nhất có thể
- [ ] Đặt
max_concurrencytheo từng workload và từng dependency - [ ] Phân loại retryable / non-retryable rõ ràng
- [ ] Thiết kế idempotent consumer cho redelivery và crash-after-commit
- [ ] Có DLQ/parking lot và runbook replay
- [ ] Đặt ngưỡng backlog, oldest age, time-to-drain để alert
- [ ] Có admission control khi backlog vượt capacity
- [ ] Tách lane cho workload khác tính chất nếu cần fairness
- [ ] Review định kỳ xem queue đang che bottleneck nào chưa được sửa tận gốc
Nên đọc tiếp bài nào trong cluster này?
Nếu anh đang thiết kế reliability layer cho backend production, nên nối bài này với các chủ đề sau:
- Transactional Outbox trong Backend để bảo đảm business write và enqueue/event publish không lệch trạng thái.
- Idempotent Consumer trong Event-Driven Production để xử lý duplicate delivery do retry, redelivery hoặc crash-after-commit.
- Dead Letter Queue trong Event-Driven Systems để tách poison message khỏi backlog bình thường.
- Adaptive Concurrency Limits trong Backend Production để điều chỉnh tốc độ worker theo tín hiệu latency/throttle thực tế.
- Bulkhead Pattern trong Backend Production để cô lập tài nguyên giữa các lane việc khác nhau.
- Circuit Breaker trong Backend Production để ngừng gọi dependency đang lỗi thay vì tiếp tục bắn queue ra ngoài.
Kết luận
Queue-based load leveling là pattern rất mạnh khi dùng đúng ngữ cảnh: workload có thể async, downstream có throughput trần, và business chấp nhận trade-off eventual completion. Nó không thay capacity planning, không thay code optimization, và càng không thay correctness.
Nếu phải tóm gọn trong một câu: queue không giải quyết overload bằng cách làm hệ thống mạnh lên; nó giải quyết overload bằng cách ép hệ thống sống trong giới hạn thật của mình một cách có kiểm soát và có quan sát được.