Trong backend production, một lỗi nhỏ hiếm khi đứng yên ở đúng nơi nó sinh ra. Một service gửi email bị chậm có thể ăn hết worker. Một endpoint search bị spike traffic có thể chiếm hết connection pool. Một downstream timeout có thể làm thread pool đầy, rồi checkout cũng chết theo dù bản thân checkout không có bug.
Bulkhead Pattern là cách thiết kế để giới hạn bán kính phá hoại của sự cố: tách tài nguyên theo luồng nghiệp vụ, theo mức ưu tiên hoặc theo dependency để một phần hệ thống quá tải không kéo sập phần còn lại. Nếu backpressure và load shedding giúp kiểm soát dòng tải, thì bulkhead giúp cô lập nơi tải đó được xử lý.
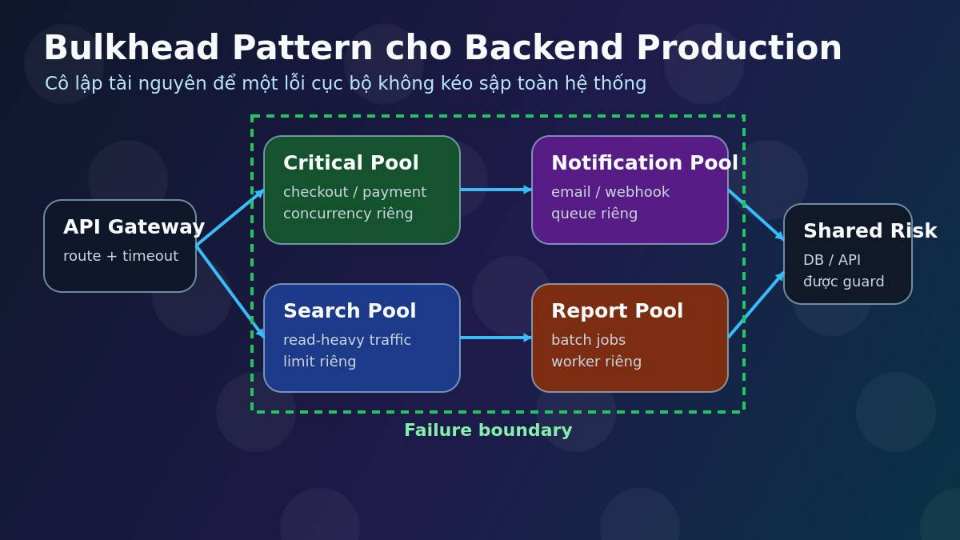
Bulkhead Pattern là gì?
Bulkhead Pattern lấy ý tưởng từ vách ngăn trên tàu: nếu một khoang bị thủng, nước không làm chìm cả con tàu ngay lập tức. Trong phần mềm, “vách ngăn” là các giới hạn tài nguyên độc lập: thread pool riêng, worker pool riêng, queue riêng, database connection pool riêng, semaphore riêng, rate limit riêng hoặc circuit breaker riêng cho từng nhóm workload.
Mục tiêu không phải làm hệ thống không bao giờ lỗi. Mục tiêu là khi một phần lỗi, phần quan trọng vẫn còn đủ tài nguyên để phục vụ người dùng.
Vì sao backend production cần Bulkhead?
Ở môi trường local, mọi request thường chạy nhẹ và ít cạnh tranh tài nguyên. Ở production, tài nguyên luôn hữu hạn: CPU, memory, thread, connection, queue capacity, file descriptor, outbound socket và cả quota của API bên thứ ba.
Không có bulkhead, các workload khác nhau thường tranh cùng một pool. Khi workload ít quan trọng gặp vấn đề, nó có thể chiếm hết tài nguyên của workload quan trọng hơn.
- Endpoint export report chiếm hết worker làm login chậm.
- Webhook retry ồ ạt chiếm hết outbound connection làm payment timeout.
- Search query nặng làm database pool đầy khiến API đọc/ghi đơn giản cũng đứng.
- Email provider chậm làm queue worker kẹt, các job critical không được xử lý.
Bulkhead khác rate limit, circuit breaker và timeout ra sao?
Các pattern này thường đi cùng nhau nhưng giải quyết các lớp khác nhau:
- Timeout: giới hạn một operation được chờ bao lâu.
- Retry budget: giới hạn số lần thử lại để retry không nhân tải.
- Circuit breaker: tạm ngắt gọi dependency đang lỗi.
- Rate limit: giới hạn tốc độ request đi vào hoặc đi ra.
- Bulkhead: giới hạn tài nguyên mà một nhóm workload được phép dùng.
Nếu chỉ có timeout nhưng dùng chung thread pool, một nhóm request vẫn có thể làm pool đầy trước khi timeout phát huy tác dụng. Bulkhead đặt “quota tài nguyên” ngay từ đầu.

Các kiểu Bulkhead phổ biến trong backend
1. Thread pool bulkhead
Tách thread pool cho luồng critical và non-critical. Ví dụ checkout/payment có pool riêng, notification/report có pool riêng. Khi report chậm, checkout không bị hết thread.
2. Connection pool bulkhead
Tách connection pool theo database hoặc theo nhóm query. Query phân tích/report không nên dùng cùng pool với transaction ghi đơn hàng nếu workload rất khác nhau.
3. Queue bulkhead
Tách queue theo priority: critical jobs, default jobs, low-priority jobs. Queue phải bounded, có chính sách reject/drop/defer rõ ràng, không để backlog vô hạn che giấu sự cố.
4. Semaphore bulkhead
Giới hạn concurrency cho một dependency hoặc một đoạn code mà không cần tách thread pool. Ví dụ chỉ cho tối đa 20 request đồng thời gọi fraud-check API.
5. Service/deployment bulkhead
Tách service, replica group hoặc node pool cho workload khác nhau. Đây là mức mạnh hơn nhưng tốn vận hành hơn, phù hợp khi boundary nghiệp vụ rõ và traffic đủ lớn.
Ví dụ thiết kế Bulkhead cho hệ thống e-commerce
Giả sử backend có các flow: xem sản phẩm, tìm kiếm, checkout, gửi email, đồng bộ CRM và xuất report. Checkout là critical path; email/report là non-critical.
critical_pool:
max_concurrency: 80
timeout_ms: 1200
routes:
- POST /checkout
- POST /payment/confirm
search_pool:
max_concurrency: 40
timeout_ms: 800
queue_size: 100
notification_queue:
workers: 8
max_retries: 3
dead_letter_queue: true
report_queue:
workers: 2
schedule: off_peak
queue_size: 50Thiết kế này không đảm bảo mọi thứ luôn nhanh. Nhưng nó đảm bảo report không được phép ăn hết worker của checkout, notification không retry vô hạn, và search có giới hạn riêng khi traffic tăng.
Checklist triển khai Bulkhead Pattern

- Phân loại workload: critical, important, best-effort, batch.
- Vẽ dependency map: route nào gọi DB/API/queue nào, timeout bao lâu.
- Đo saturation hiện tại: thread usage, queue depth, connection pool wait time, p95/p99 latency.
- Đặt giới hạn ban đầu nhỏ: max concurrency, queue size, worker count, pool size.
- Định nghĩa hành vi khi đầy: 429, 503, degrade, enqueue later, dead-letter, hoặc drop nếu dữ liệu không critical.
- Gắn observability: metric theo từng bulkhead, không chỉ metric toàn service.
- Canary rollout: bật theo một route/tenant/percentage trước khi áp dụng toàn hệ thống.
Những lỗi thường gặp khi dùng Bulkhead
Tách quá nhỏ khi chưa có dữ liệu
Nếu boundary quá vụn, hệ thống khó vận hành và dễ underutilized. Bắt đầu từ 3–4 nhóm rõ: critical, read-heavy, async, batch.
Queue không bounded
Queue vô hạn chỉ chuyển sự cố từ request latency sang memory/backlog. Bulkhead tốt cần giới hạn queue và có policy khi đầy.
Retry làm vỡ bulkhead
Nếu retry không có jitter, backoff và budget, retry có thể nhân tải lên dependency đang yếu. Luôn thiết kế retry cùng timeout và circuit breaker.
Không monitor theo boundary
Nếu chỉ nhìn CPU/service latency tổng, anh sẽ không biết pool nào đang đầy. Cần metric riêng cho từng pool/queue/dependency.
Khi nào nên áp dụng Bulkhead?
Bulkhead đáng làm khi hệ thống có nhiều loại workload dùng chung tài nguyên, đã từng gặp cascade failure, có flow critical cần bảo vệ, hoặc dependency bên ngoài không ổn định. Với hệ thống nhỏ, có thể bắt đầu đơn giản bằng bounded queue, timeout, semaphore concurrency limit và tách worker critical/non-critical.
Nếu team đang xây backend production, bulkhead nên đi cùng distributed tracing, postmortem sau sự cố, zero-downtime migration và tư duy system design cho backend developer.
Kết luận
Bulkhead Pattern không phải pattern hào nhoáng, nhưng rất thực dụng trong production engineering. Nó buộc team trả lời câu hỏi quan trọng: phần nào của hệ thống được phép hy sinh khi quá tải, và phần nào phải được bảo vệ bằng tài nguyên riêng?
Khi traffic tăng hoặc dependency yếu đi, hệ thống tốt không cố xử lý mọi thứ bằng mọi giá. Nó giữ phần lõi sống, degrade phần ít quan trọng và cho operator đủ tín hiệu để can thiệp. Đó là khác biệt giữa backend “chạy được” và backend đủ trưởng thành cho production.